第 17 章 AI 赋能
17.1 AI 插件
17.1.1 几款主流的 AI 代码生成插件
以下是几款主流的 AI 代码生成插件(支持 JetBrains IDE/VS Code 等),从技术、功能、适用场景等维度进行对比分析,供参考:
| 工具名称 | 开发公司 | 核心技术模型 | 核心优势 | 适用场景 | 定价 |
|---|---|---|---|---|---|
| GitHub Copilot | GitHub (微软) | OpenAI GPT-4 Turbo | - 多语言支持广(Python/JS/TS 等) - 深度集成 GitHub 生态 - 智能代码补全与测试生成 | 全栈开发、开源项目、企业级 DevOps | $10/月(个人) $19/月(企业) |
| Amazon CodeWhisperer | AWS | 自研模型(基于 AWS 代码库) | - 完全免费 - 优化 AWS 服务开发(Lambda/S3 等) - 代码安全扫描 | AWS 云原生开发、Python/Java 项目 | 免费 |
| Codeium | Codeium Inc. | 自研模型(Cascade) | - 完全免费(个人版) - 支持 70+ 语言 - 内置代码搜索 & 聊天功能 | 个人开发者、多语言项目、快速原型 | 免费(企业版收费) |
| Tabnine | Tabnine Inc. | 自研模型 + StarCoder | - 企业级隐私(支持本地部署) - 适应团队代码风格 - 30%+ 代码自动化生成 | 金融/军工等高安全需求开发 | 免费版 + 企业版(定制定价) |
| 通义灵码 | 阿里云 | 通义千问(Qwen3) | - 中文优化 - 支持 Java/微服务/云原生 - 智能体模式(@workspace) | 国内开发者、阿里云生态项目 | 免费(企业版收费) |
| CodeArts Snap | 华为 | 盘古大模型 | - 适配 昇腾芯片 - 支持硬件/物联网开发 - 企业级安全合规 | 政企/国产化项目、嵌入式开发 | 免费 |
| Comate | 百度 | 文心大模型(ERNIE Code) | - 中文语义理解强 - 低代码生成优化 - 适合教育/文档密集型项目 | 国内 Web/AI 开发、教学场景 | 免费 |
| MarsCode | 字节跳动 | 豆包 1.5-pro + DeepSeek-V3 | - 轻量级 AI 插件 - 适合快速补全与调试 - 字节生态集成(如飞书) | 个人开发者、小程序/H5 开发 | 免费 |
| Tencent Cloud CodeBuddy | 腾讯 | 混元 Turbo S | - 微信生态优化(小程序/H5) - 腾讯云深度集成 - 企业研效看板 | 腾讯云开发者、游戏后端开发 | 免费(企业版收费) |
项目如何选择?
- 优先免费 → 通义灵码、Codeium、CodeWhisperer。
- 企业级合规 → Tabnine(离线版)、CodeArts Snap。
- 全栈开发 → Copilot 或 Codeium(语言覆盖广)。
- 国内云原生 → 通义灵码(阿里云)或 CodeArts Snap(华为云)。
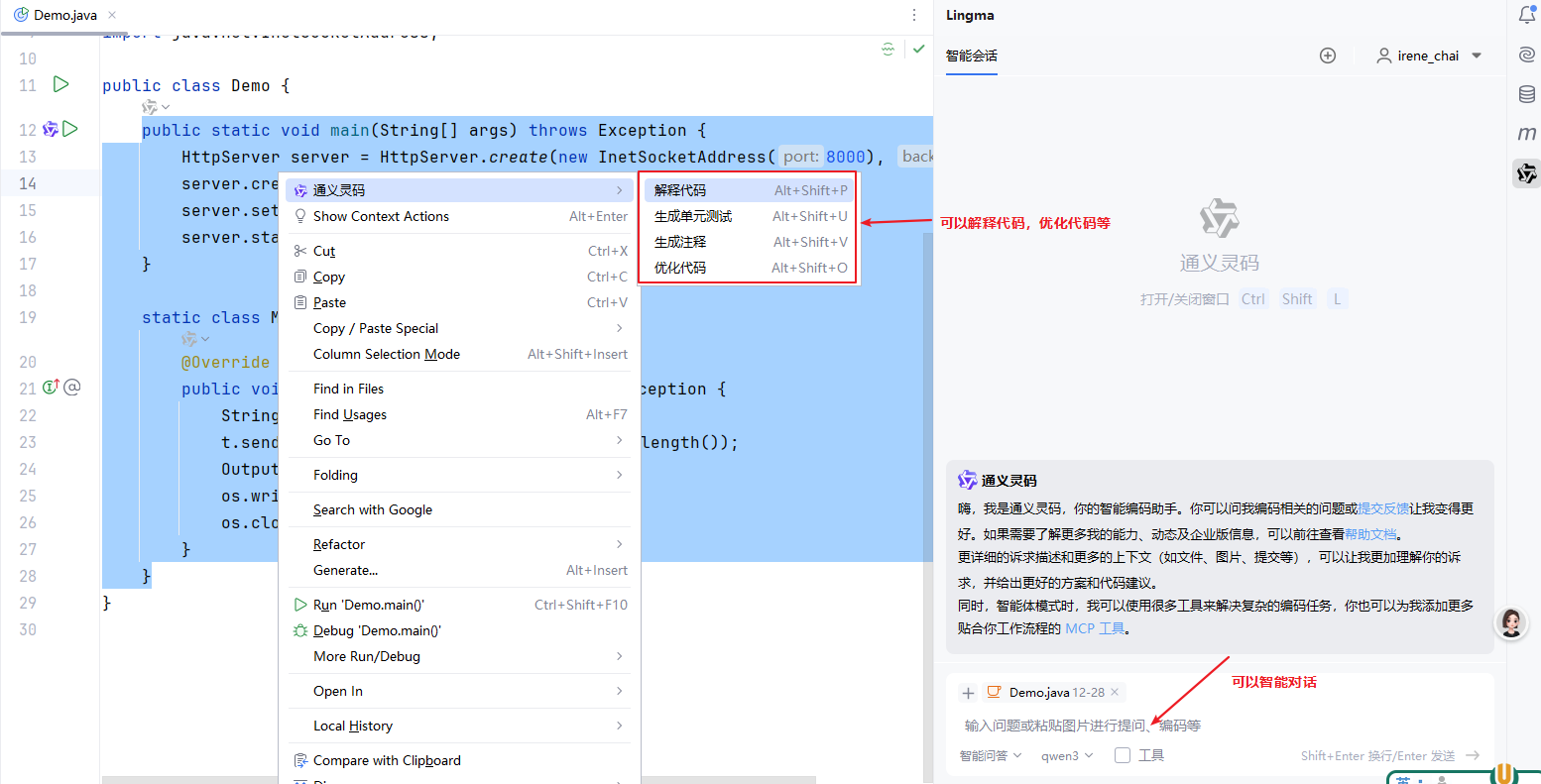
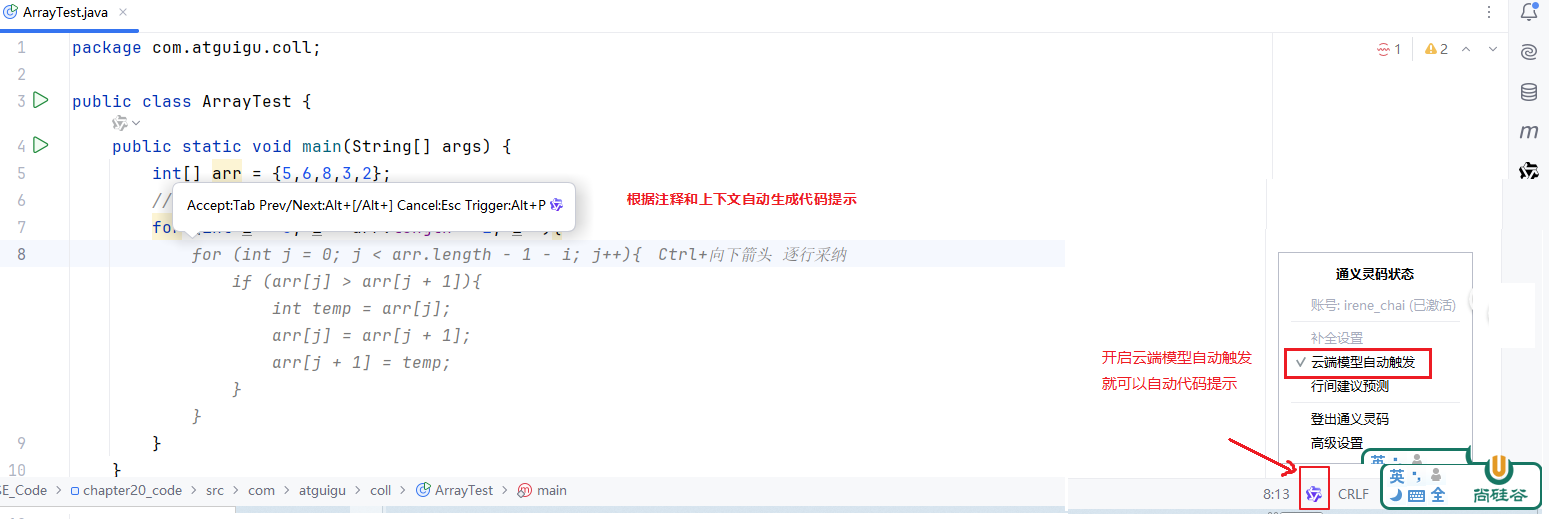
17.1.2 通义灵码
初学者如何选择?通义灵码
- 中文注释与需求理解:通义灵码对中文注释的代码生成和解释更准确,初学者常用中文提问或写注释,能更直观地理解 AI 的反馈。
- 减少干扰:通义灵码的推荐相对保守,不会像 Copilot 那样频繁弹出建议,避免初学阶段信息过载。
- 本地知识库:对国内 Java 生态(如阿里系框架、国产数据库等)的支持更好,示例代码更贴近国内企业常用技术栈。
- 无需海外账号:直接使用阿里云账号即可,规避 GitHub Copilot 的订阅和网络访问问题。
17.2 AI 代码审查工具
17.2.1 几款主流的 AI 代码审查工具
| 工具名称 | 开发公司 | 核心技术模型 | 核心优势 | 适用场景 | 定价 |
|---|---|---|---|---|---|
| GitHub Copilot X+ | GitHub (微软) | GPT-5 微调模型 + 代码知识图谱 | - 实时漏洞修复(CVE 2025 集成) - 单元测试覆盖率预测(92% 准确率) - 法律合规扫描(23 项 AI 法规) | 企业级 DevOps、开源项目维护 | $10/月(个人) $19/月(企业) |
| SonarQube 12.0 | SonarSource | 量子计算驱动的技术债务预测 | - 金融级代码检测(中国银保监会指定) - AI 生成代码专项检测(ChatGPT 5 逻辑错误识别) | 金融系统、高安全性代码审查 | 企业版收费(需咨询) |
| DeepSource 2025 | DeepSource | 微服务依赖图谱 + 自动重构 | - 代码异味自动重构(节省 75% 技术债时间) - 精准定位微服务雪崩风险点 | 大型分布式系统(如 Uber 万级微服务) | 企业定制化方案 |
| Snyk Code Pro | Snyk | 零日漏洞预测 + IaC 合规审计 | - 云原生安全扫描(Terraform/AWS 配置检测) - 阿里云实测降低 90% 泄露风险 | DevSecOps、云基础设施安全 | 免费版 + 企业版 |
| Amazon CodeWhisperer Pro | AWS | 自研模型(AWS 代码库优化) | - 代码性能与云成本联动优化(标注 AWS 费用影响) - Serverless 冷启动预测(毫秒级精度) | AWS 云开发、Serverless 架构 | 免费(个人版) |
| CodeRabbit | CodeRabbit | 上下文感知 + AST 模式分析 | - 免费 支持 VS Code / Cursor / Windsurf - 实时 Git PR 审查(减少 50% 手动审查时间) | 开源项目、敏捷团队 | 免费(公共仓库) |
| Codacy Defense | Codacy | 大模型提示词审查 + 专利相似度检测 | - 拦截 GitHub 开源项目 License 违规 - 阻断恶意 AI 指令注入 | 开源合规、企业 IP 保护 | 企业定制化 |
| Devika(开源) | StitionAI | Claude 3 / GPT-4 + 多步任务分解 | - 完全开源,支持本地 Ollama 部署 - 自动安全审计 + 修复建议(CVE 检测) | 安全敏感项目、DevSecOps | 免费 |
项目中如何选择?
- 企业合规 → SonarQube / Codacy Defense
- 云原生开发 → Snyk Code Pro / CodeWhisperer
- 开源项目 → CodeRabbit / Devika
- 隐私敏感 → Tabnine(本地部署)/ Devika(开源)
17.2.2 SonarQube 插件
初学者如何选择?
本课程暂时选择 SonarQube,个人使用暂时免费,IDEA 中有对应的插件。
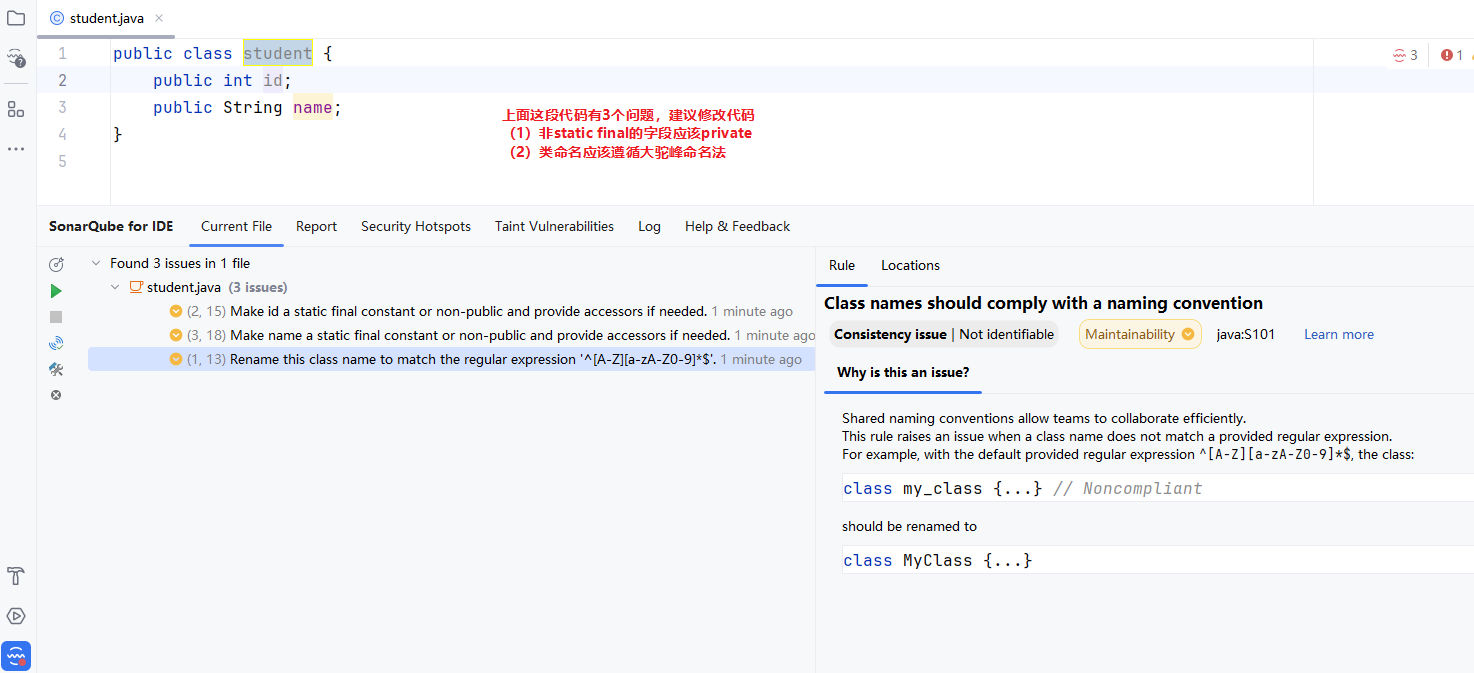
17.3 Trae
17.3.1 几款 AI 原生 IDE
以下是几款与 Trae(字节跳动的 AI 原生 IDE)同类型的 AI 开发工具,它们均采用 AI 原生设计,支持自然语言编程、智能代码生成和全流程开发辅助:
| 工具名称 | 开发公司 | AI 模型 | 核心优势 | 适用场景 | 定价 |
|---|---|---|---|---|---|
| Cursor | Anysphere | Claude 3.5 Sonnet、GPT-4o、DeepSeek-V3(可自定义) | - 项目级代码理解(@Codebase) - Composer 多文件编辑 - 智能预测 & 自动修复 | 全栈开发、复杂项目重构、企业级应用 | $20/月(Pro 版) |
| Windsurf | Codeium | Cascade(自研)、Claude 3.5、GPT-4o | - Agent 模式(多步任务执行) - 上下文固定(Context Pinning) - 新手友好 UI | 中小型项目、团队协作、快速迭代开发 | $15/月(Pro 版) |
| Bolt.new | StackBlitz | 自研模型(未公开) | - 浏览器内全栈开发 - 对话式 AI 编程 - 云端协作 | Web 开发、快速原型验证 | $20/月(Pro 版) |
| Copilot++ | GitHub(微软) | GPT-4 Turbo、Claude 3.5(可选) | - GitHub 深度集成 - CI/CD 自动化 - 企业级安全 | GitHub 生态、企业 DevOps 流程 | $10/月(个人版) |
| Continue | Continue 团队(国际开源社区) | 支持 Llama 3、DeepSeek、Ollama(本地部署) | - 完全离线运行 - 隐私优先 - 可微调本地模型 | 金融/军工等高安全需求开发 | 免费(需本地算力) |
| Trae | 字节跳动 | 豆包 1.5-pro、DeepSeek R1/V3、GPT-4o(国际版) | - Builder 模式(自然语言生成项目) - 中文优化 - 腾讯/阿里云集成 | 国内开发者、全栈 AI 开发 | 免费(国内版) |
| CodeFlying | 码上飞团队 | 自研模型(低代码优化) | - 低代码 + AI 生成 - 全流程自动化 - 适配微信小程序/H5 | 快速应用开发、初创团队 | 免费试用(企业版收费) |
补充说明:
- Cursor 和 Windsurf 是目前最接近的竞品,Cursor 更适合 复杂项目,Windsurf 在 Agent 模式 上表现更优。
- Copilot++ 是 GitHub Copilot 的升级版,适合 GitHub 生态开发者,但缺乏多文件编辑能力。
- Continue 是唯一支持 完全离线运行 的工具,适合 隐私敏感行业。
- Trae 和 CodeFlying 主要面向 国内开发者,Trae 更偏向 全栈 AI 开发,而 CodeFlying 专注 低代码生成
如何选择?
- 国内开发者 → Trae(免费、中文优化)。
- 国际团队 → Cursor(GPT-4 支持)。
- 隐私敏感项目 → Continue(本地运行)。
- Web 开发 → Bolt.new(云端协作)。
初学者如何选择?
- Trae:适合国内 Java 初学者,中文支持好、免费、快速上手,能帮助学生快速理解业务代码逻辑。
- Cursor:收费,在多语言混合项目(如 Java+Python)中表现更优,但对纯 Java 初学者帮助有限,后续需要学习国际化项目(如微服务+TypeScript),可再引入 Cursor
17.3.2 下载安装
Trae(/treɪ/,The Real AI Engineer)IDE 与 AI 深度集成,提供智能问答、代码自动补全以及基于 Agent 的 AI 自动编程能力。使用 Trae 开发项目时,你可以与 AI 灵活协作,提升开发效率。

17.3.3 管理项目
你可以管理 Trae 中的项目,包括创建项目和切换项目。
什么是 “工作空间”?
“工作空间” 通常为一个在 Trae 中打开的文件夹。若你的项目较为复杂,也可以将多个文件夹添加至一个 “工作空间”。
创建项目
Trae 提供三种创建项目的方式:导入本地文件夹、从 GitHub 克隆仓库、从 Git 仓库的 URL 克隆。
下面演示导入本地文件夹的方式(后面大家学习了 Git 和 GitHub 之后再试另外 2 种方式)
1.点击左侧面板中央的 打开文件夹 按钮,或在界面左上角点击 选择项目 > 打开文件夹。
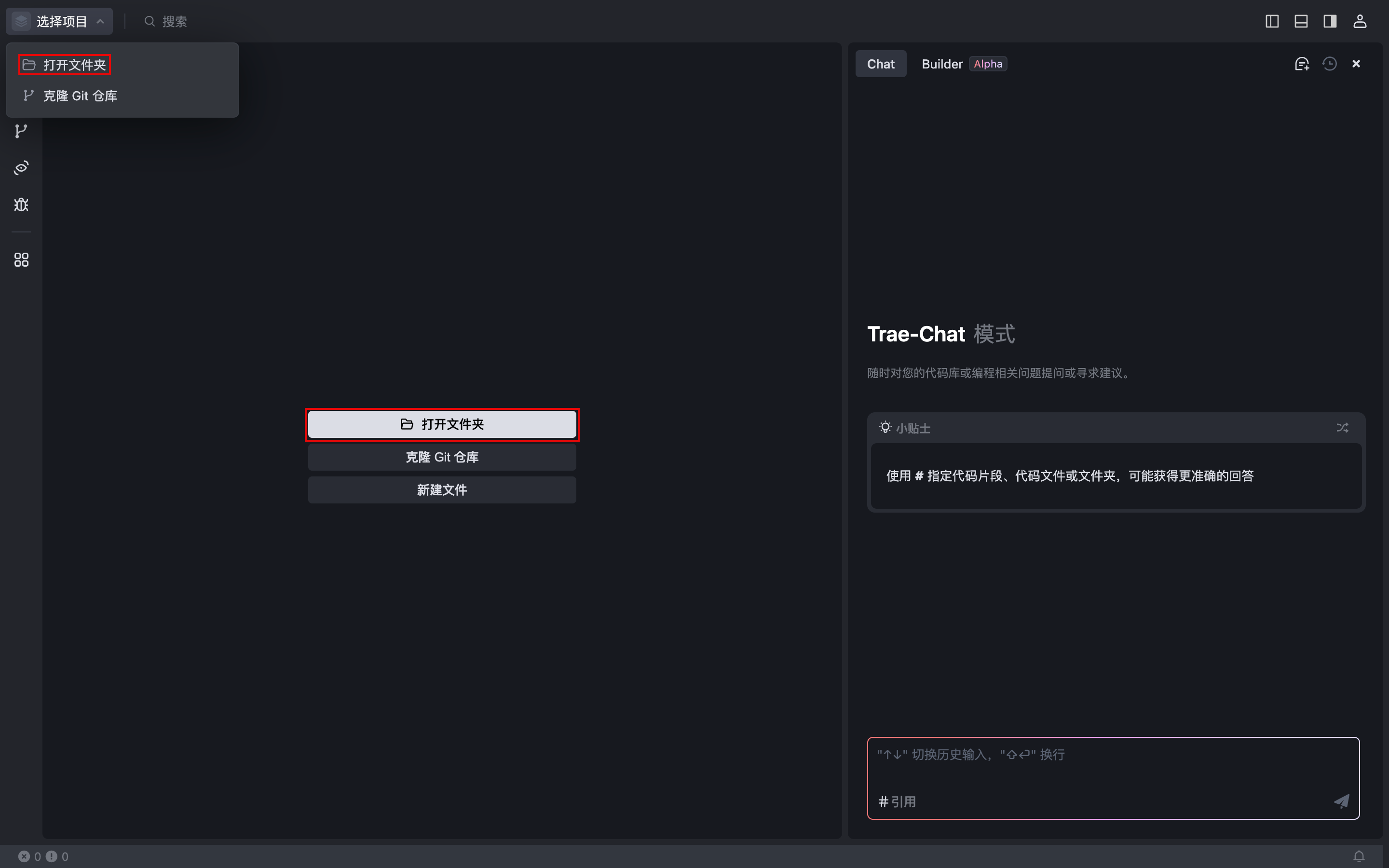
2.选择文件夹并在 Trae 中将其打开。
你将看到以下授权弹窗:
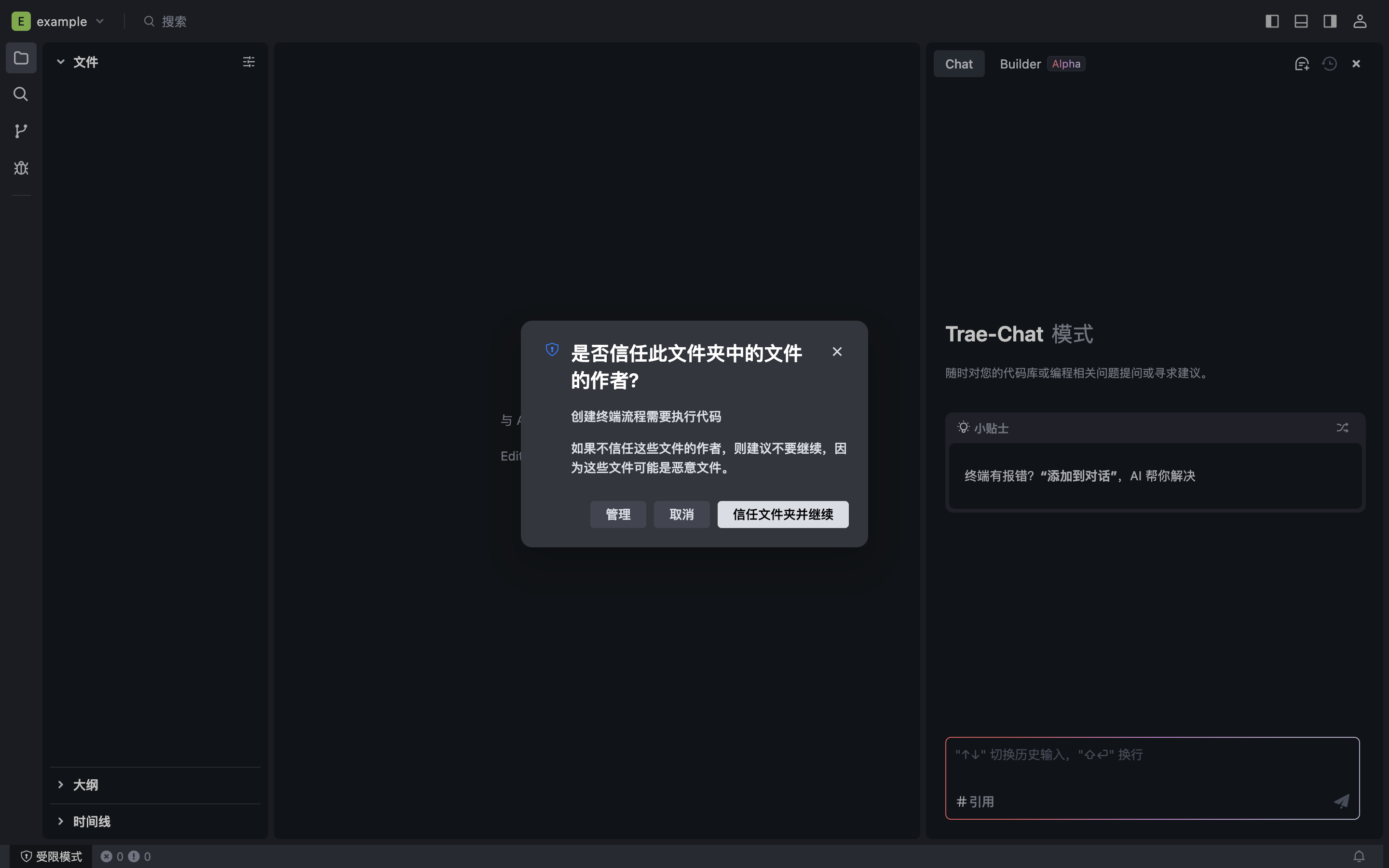
3.根据提示完成授权。
文件夹已在 IDE 中打开,你可以开始编辑项目。
17.3.4 插件管理
在 Trae 中,你可以安装、禁用和卸载插件。
安装插件
你可以从 Trae 或 VS Code 的插件市场安装插件,或直接将本地的 .vsix 文件导入至 Trae IDE。
这里演示从 Trae 的插件市场安装
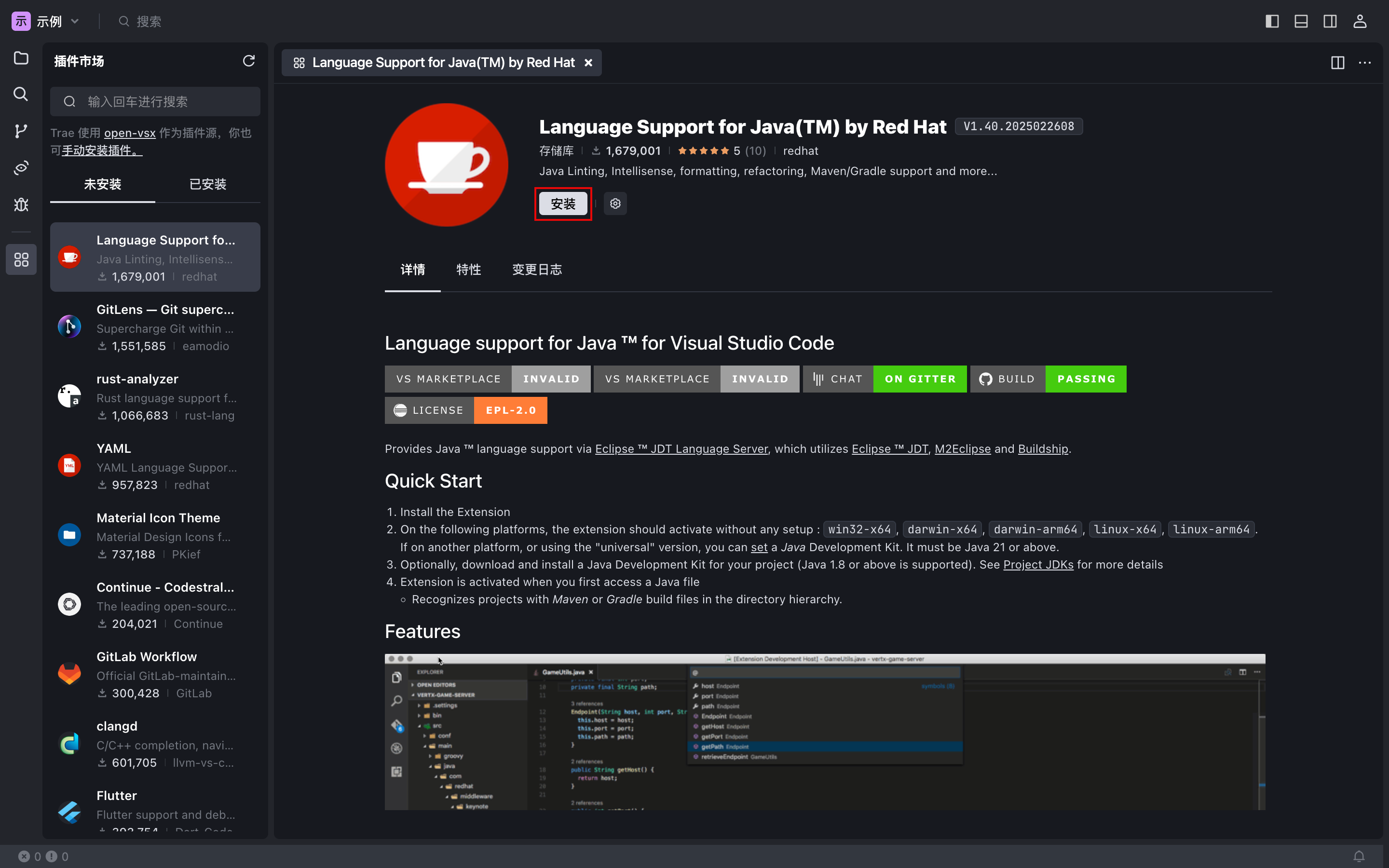
1.在左侧导航栏中,点击 插件市场 图标。
2.搜索你想要的插件并在 未安装 列表中将其选中。
界面上显示该插件的详情窗口,展示该插件的详细说明、变更日志等信息。
3.点击 安装。
Trae 开始安装该插件。安装完成后,该插件会出现在 已安装 列表中。
禁用插件
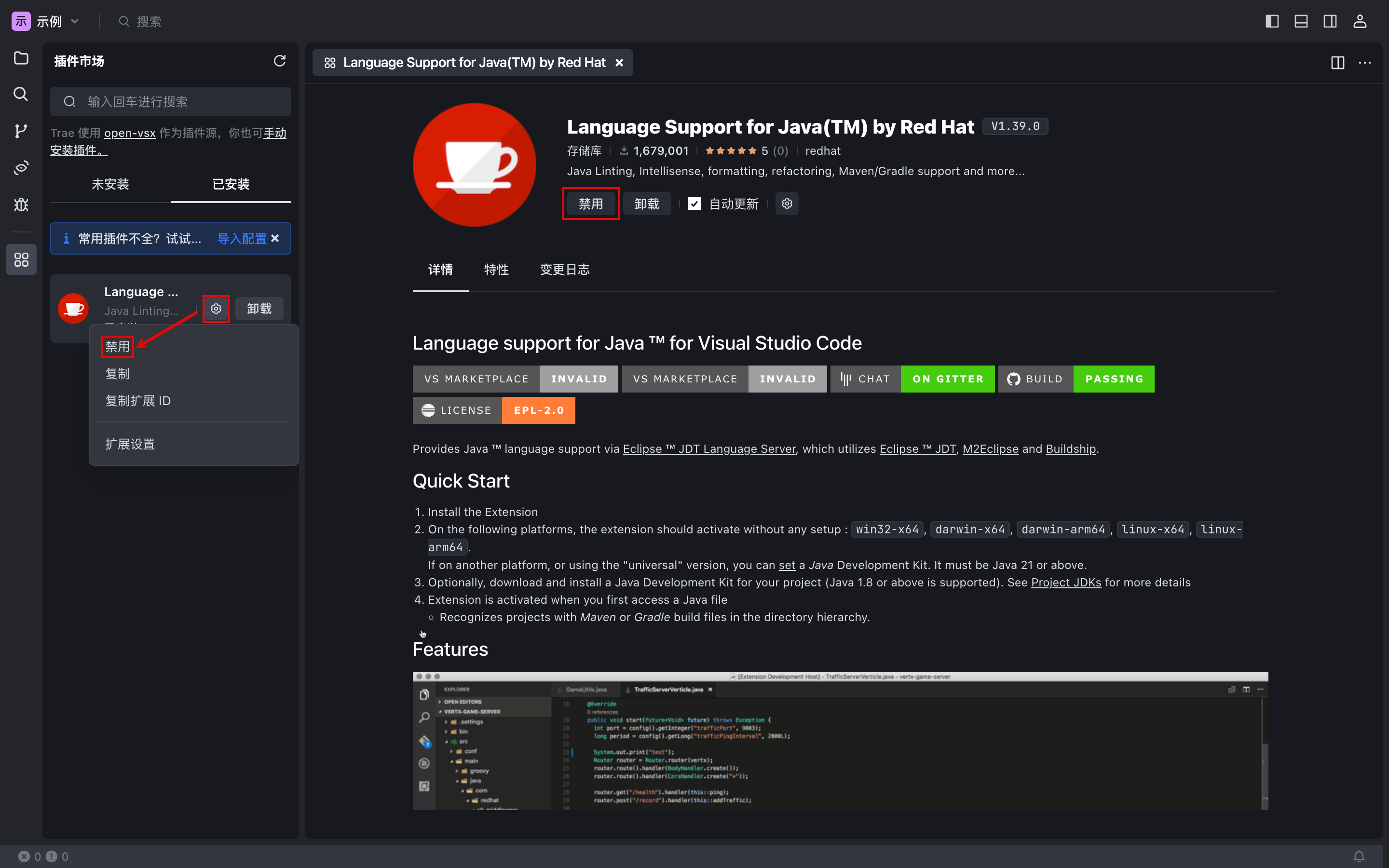
- 在 Trae 中,打开插件市场。
- 在 已安装 列表中,找到需禁用的插件。
- 鼠标悬浮至列表中的插件,然后点击 设置 > 禁用。
或
点击该插件以打开其详情窗口,然后点击 禁用。
卸载插件
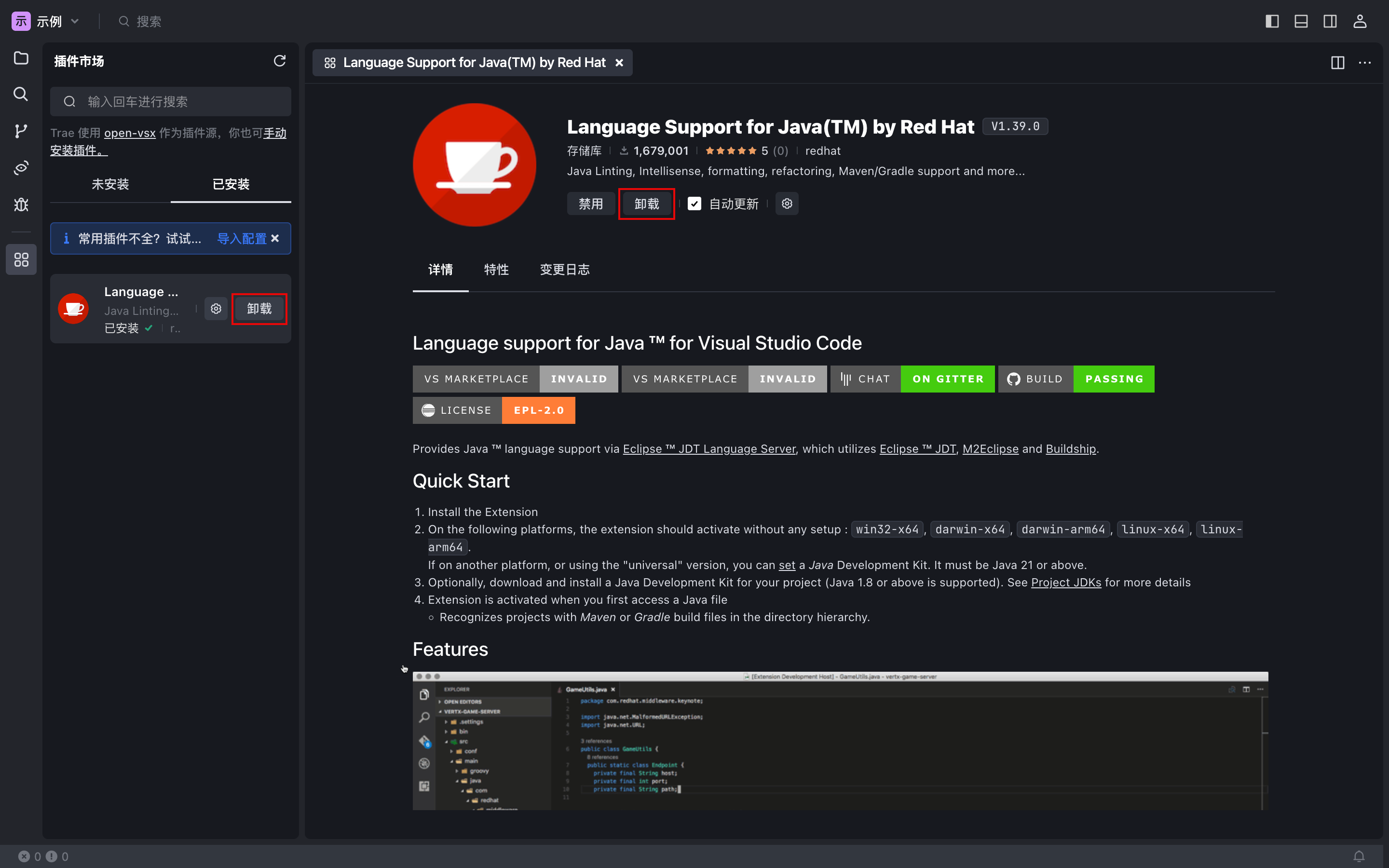
- 在 Trae 中,打开插件市场。
- 在 已安装 列表中,找到需卸载的插件。
- 鼠标悬浮至该插件,然后点击 卸载。
或
点击该插件以打开其详情窗口,然后点击 卸载。
17.3.5 cue
cue (暗示、提示)是 Trae 提供的智能编程工具,支持代码补全、多行修改、修改点预测、修改点跳转功能。
功能展示
- 代码自动补全:理解当前文件中的已有代码,自动续写相关代码。
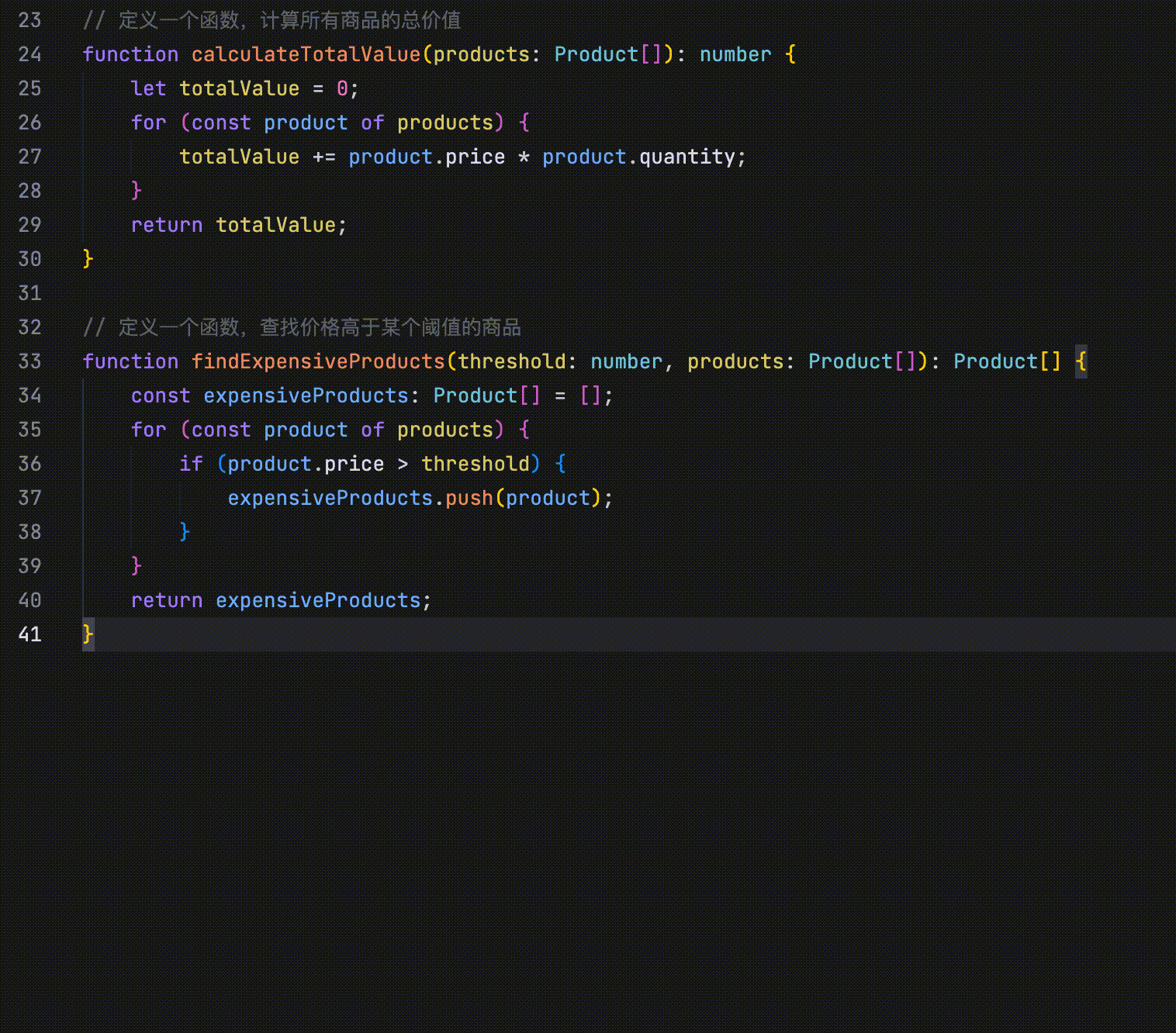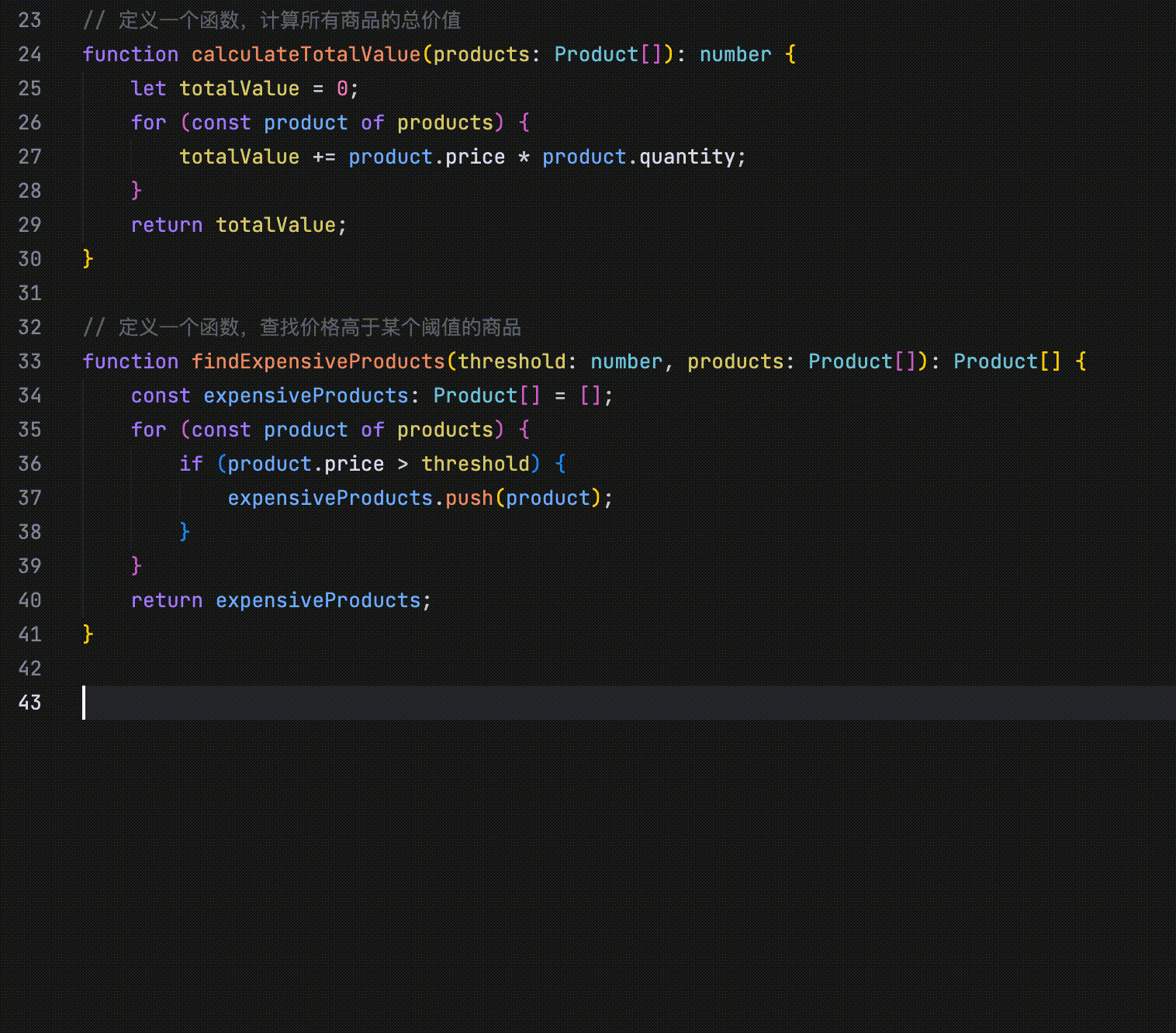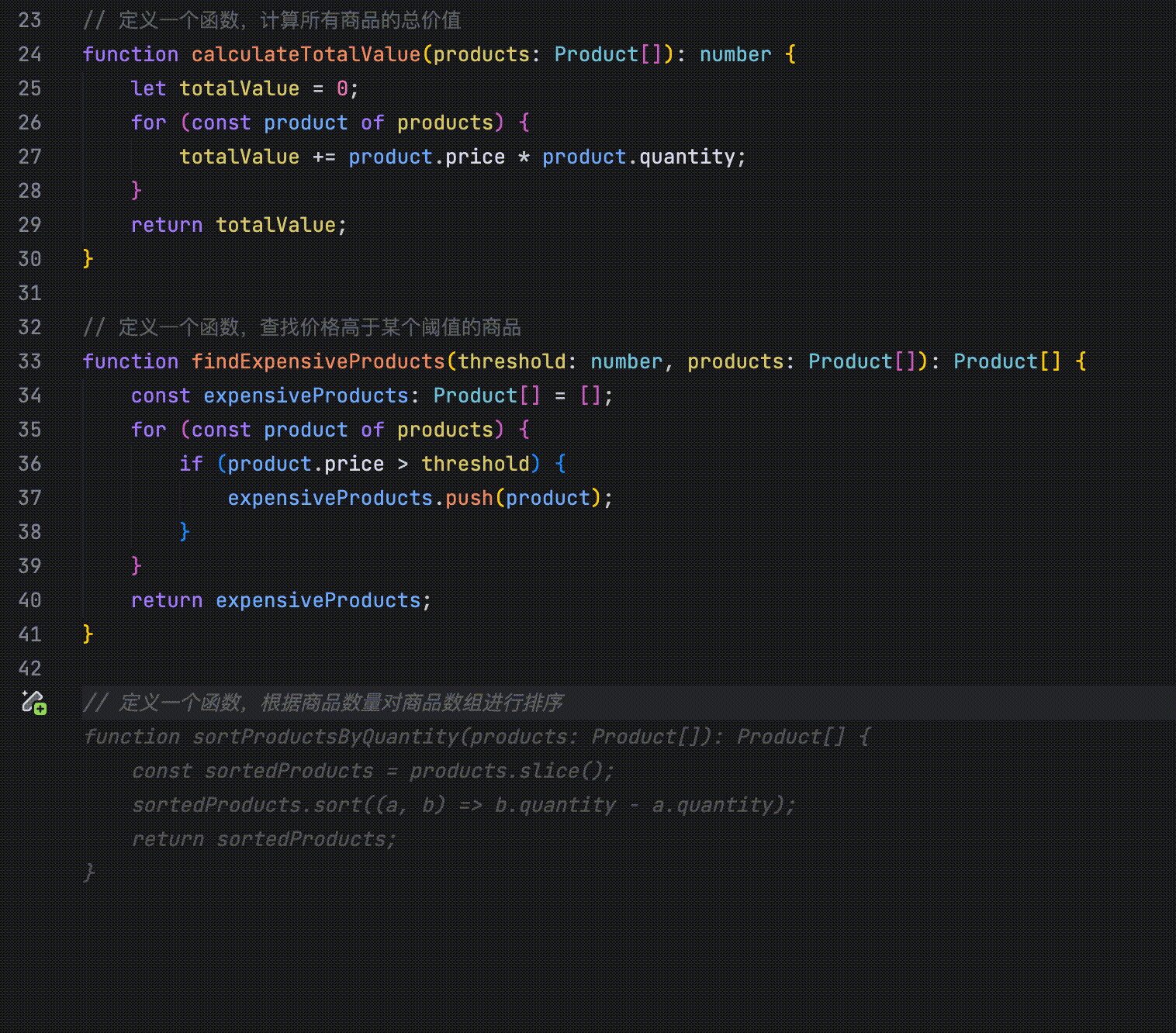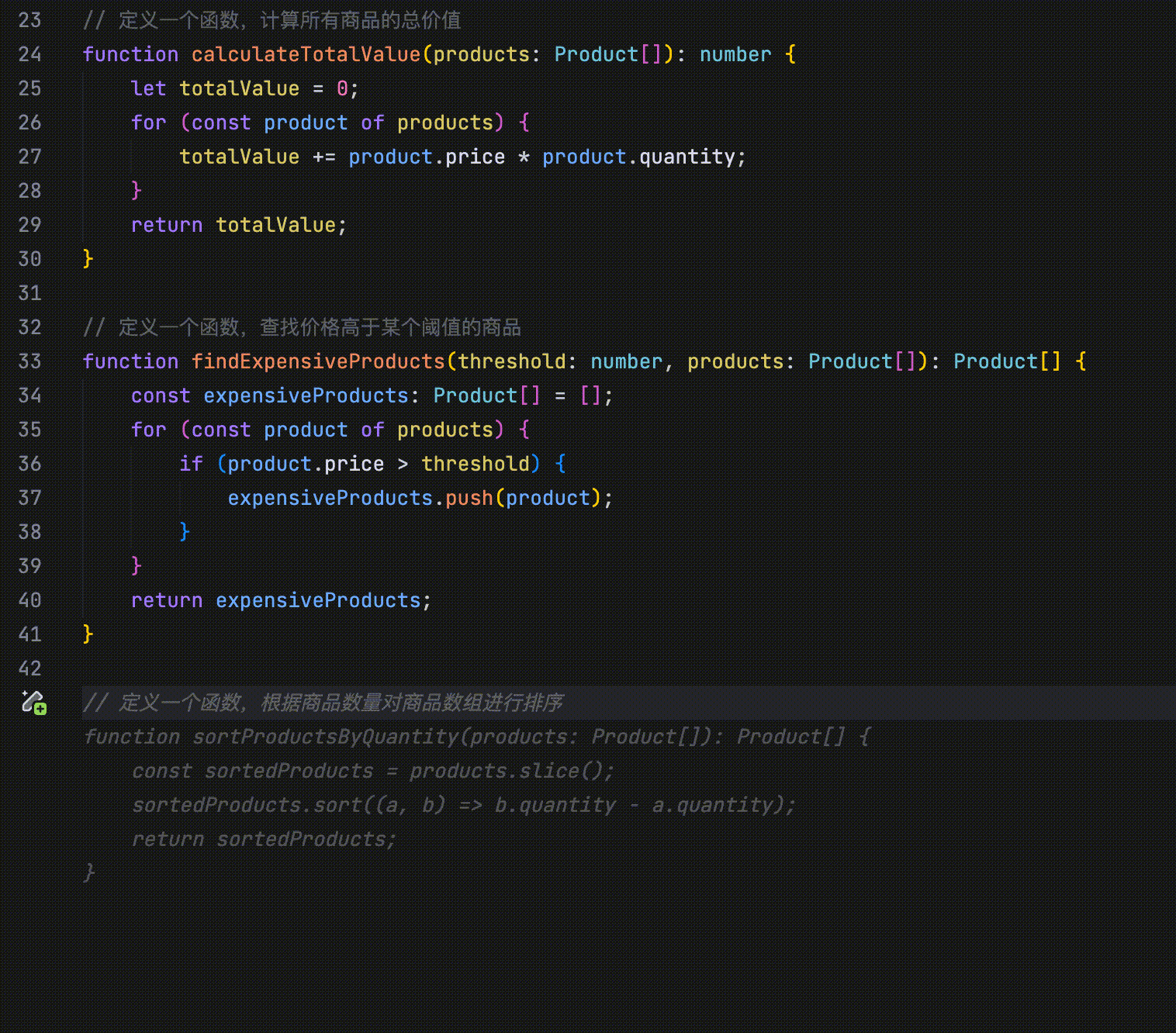
- 多行修改:通过感知上下文,AI 能够同时提供多个代码行的建议修改点。
在以下示例中,修改函数的说明后,AI 会展示与该修改相关的多行代码,并指出相应的修改点。
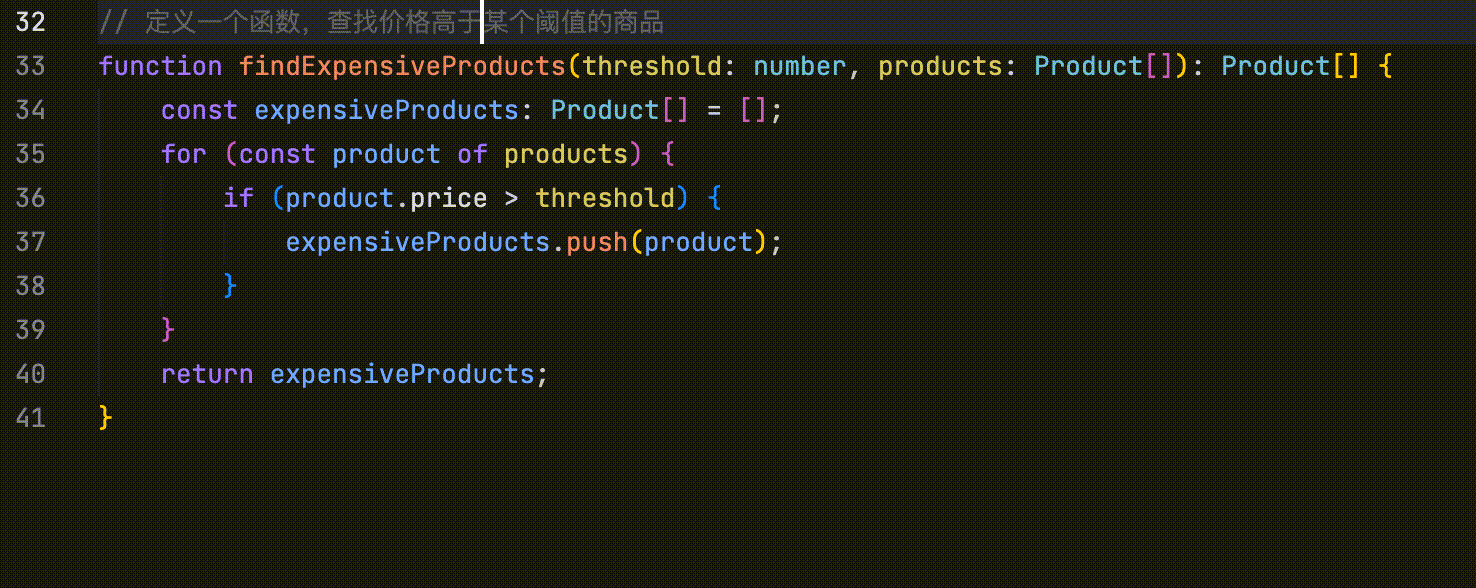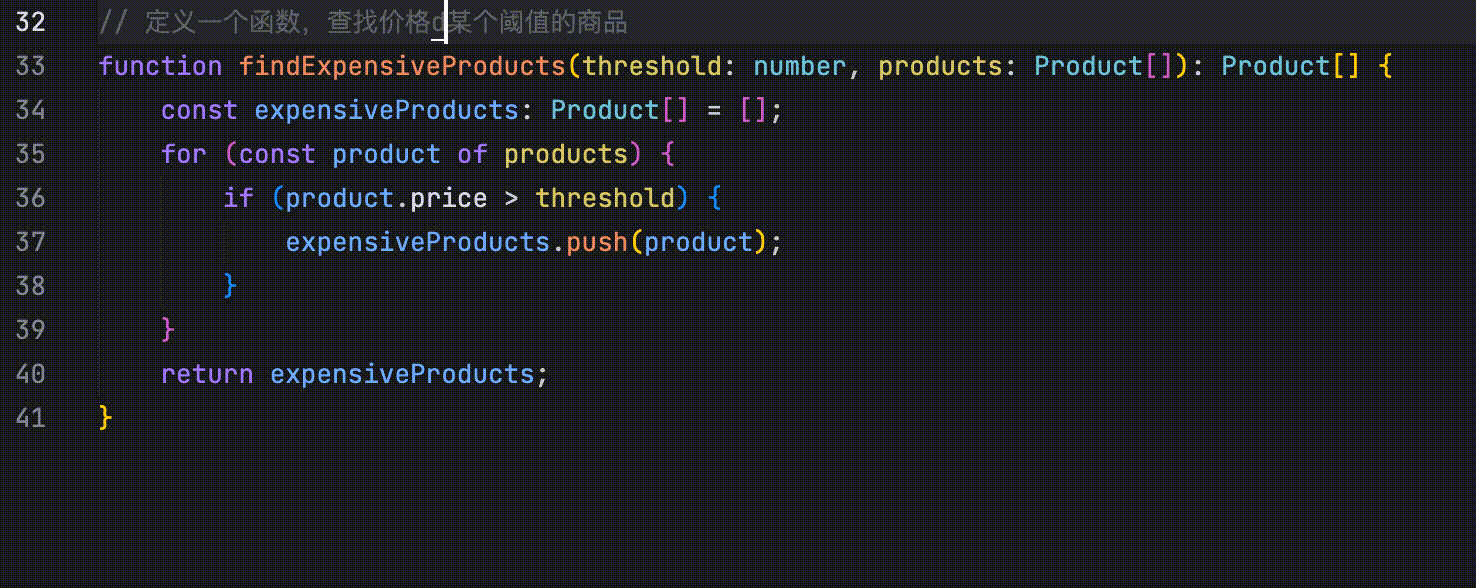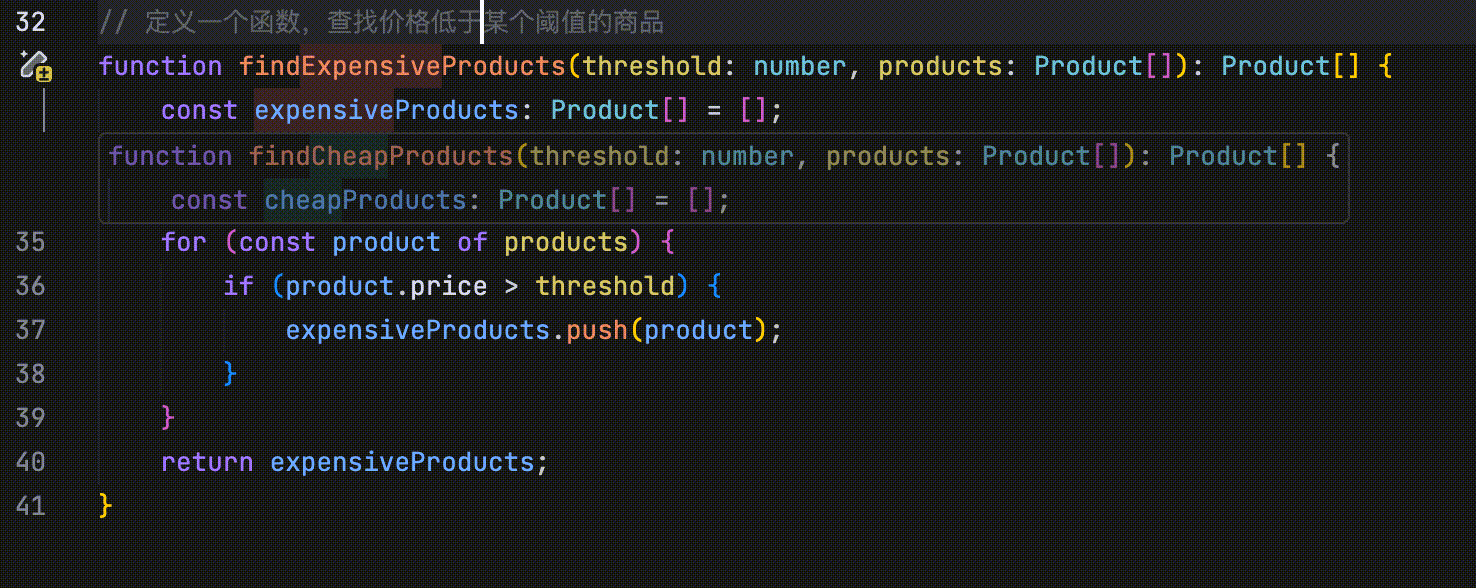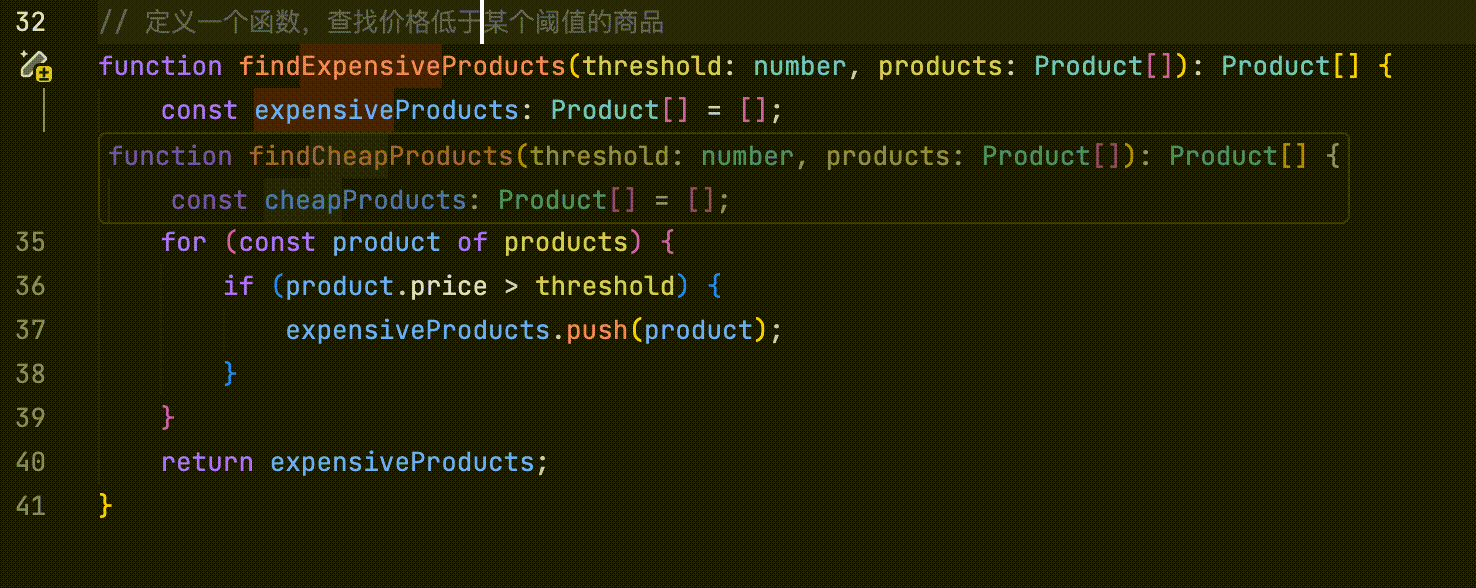
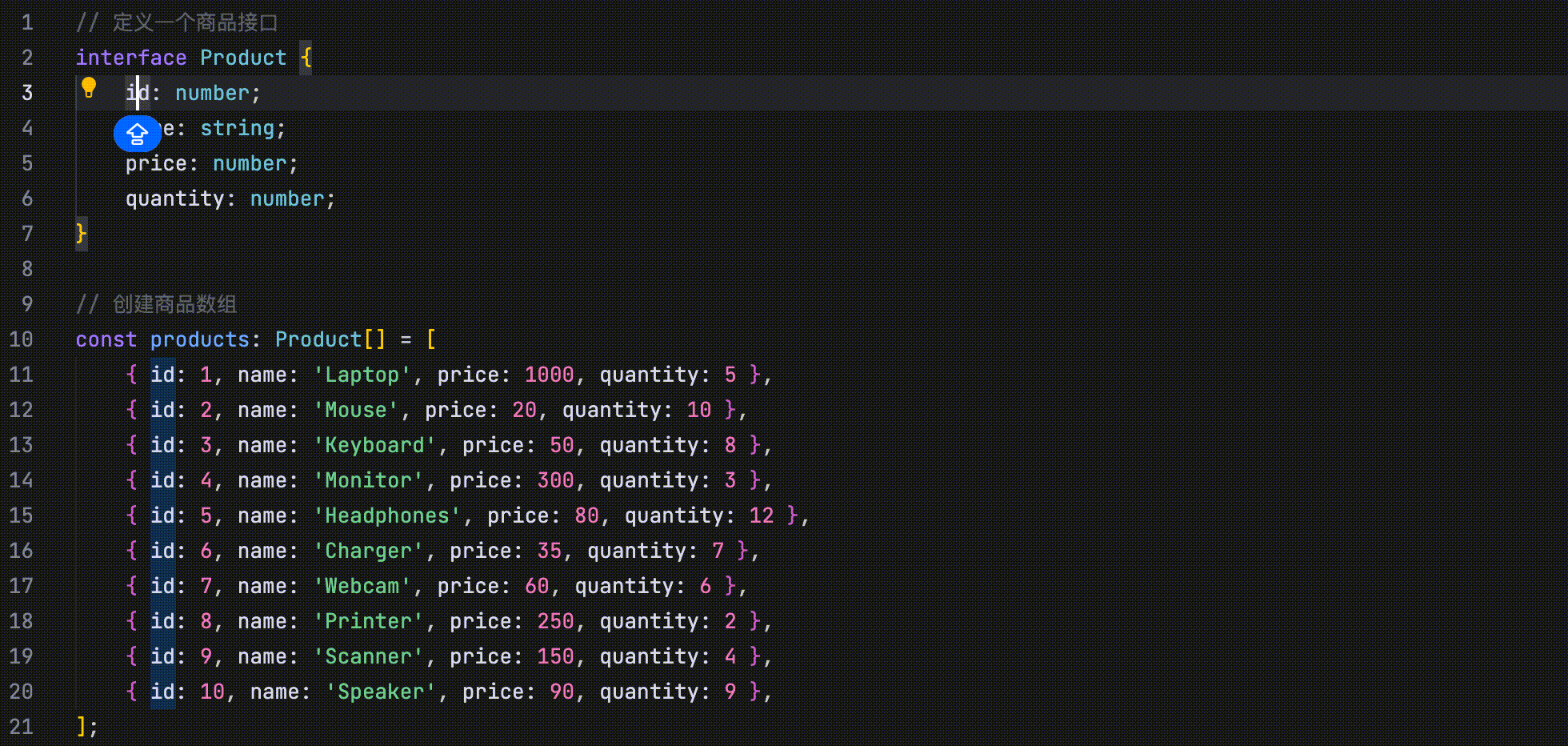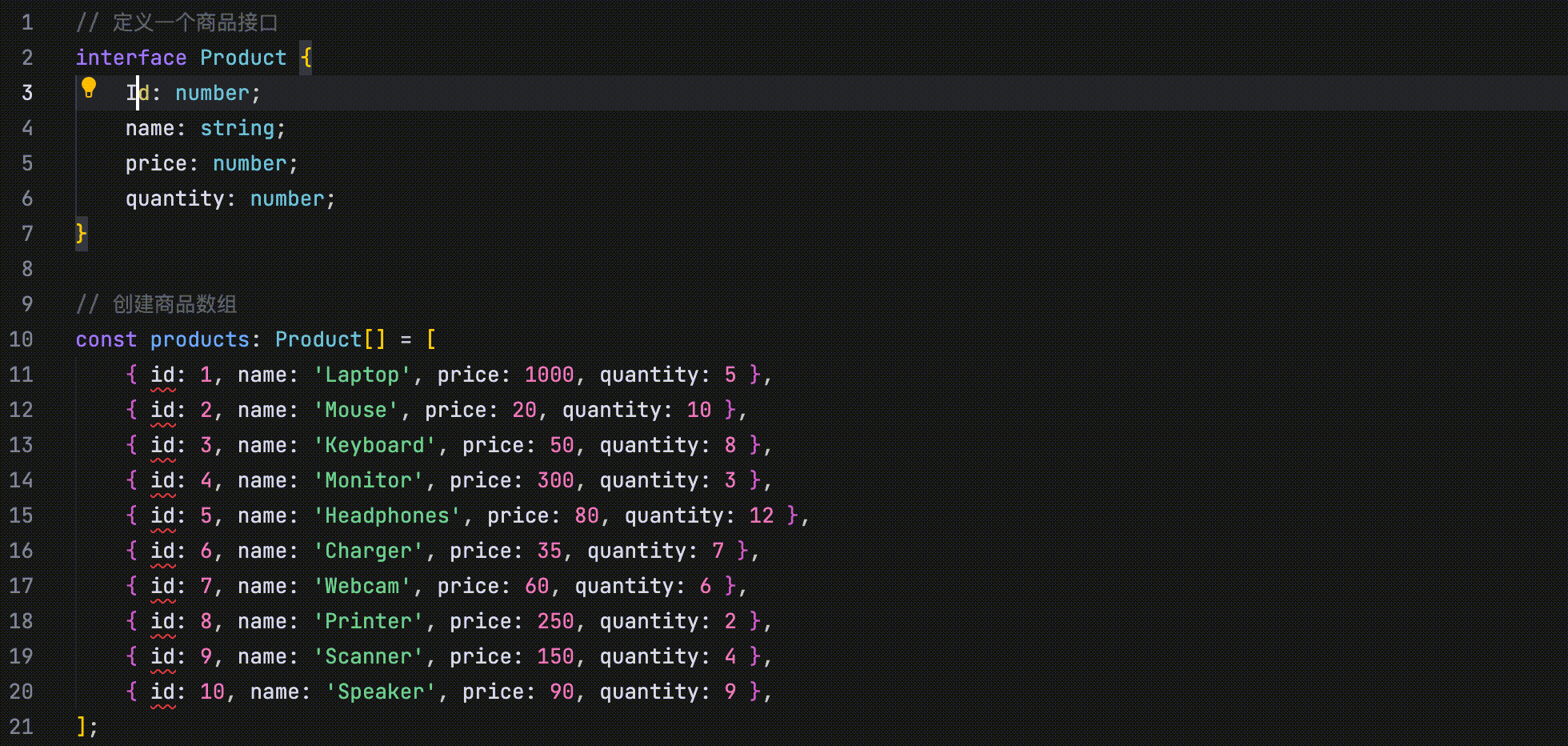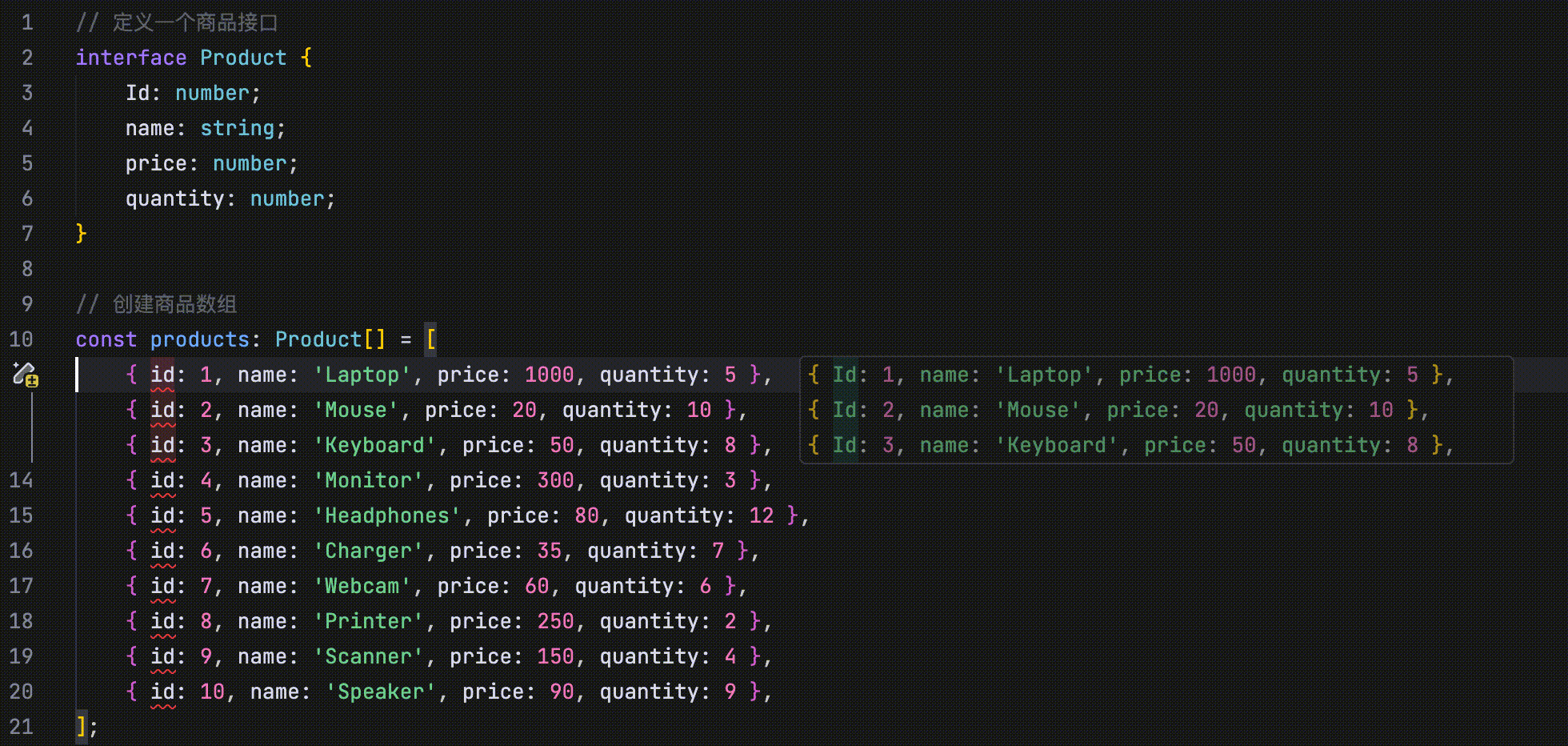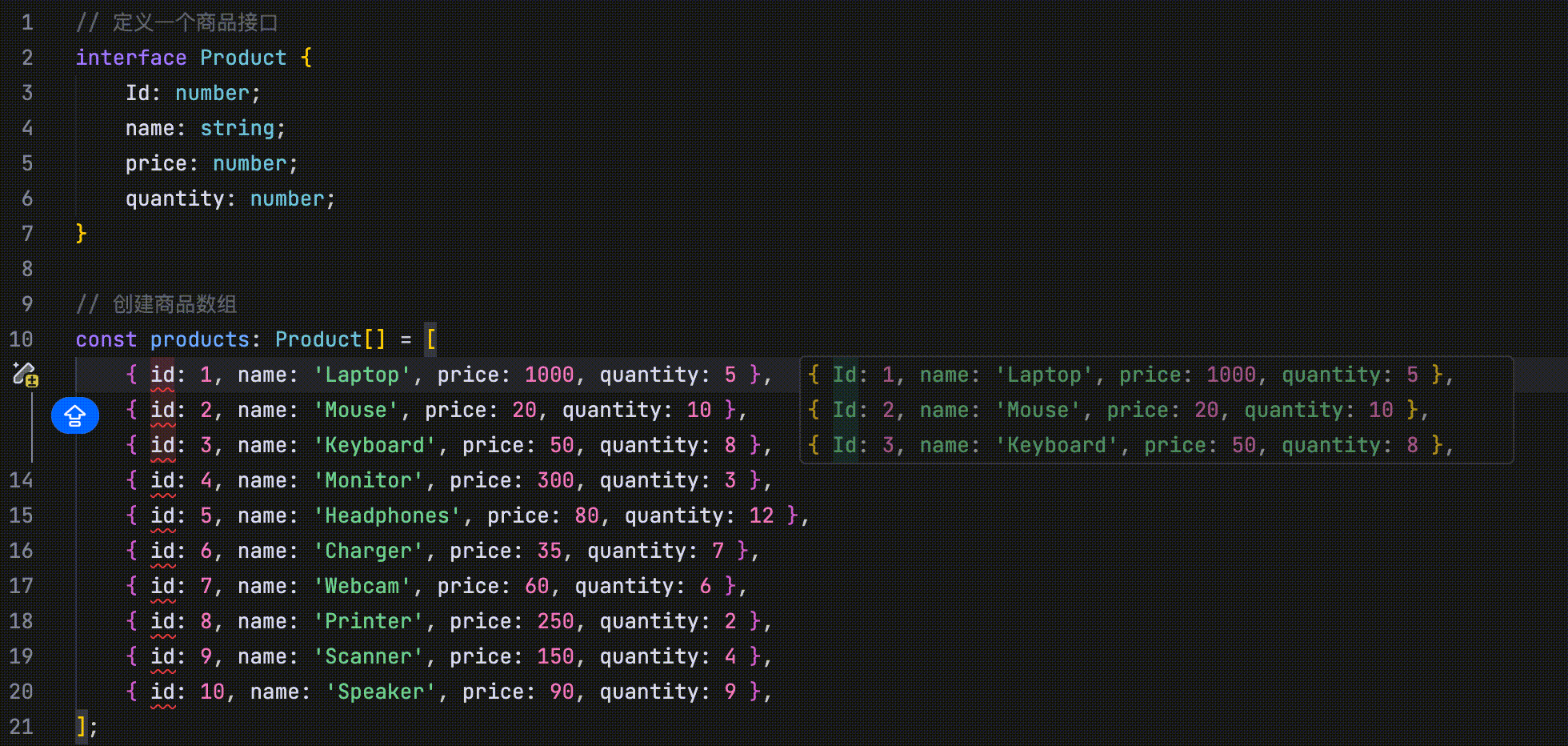
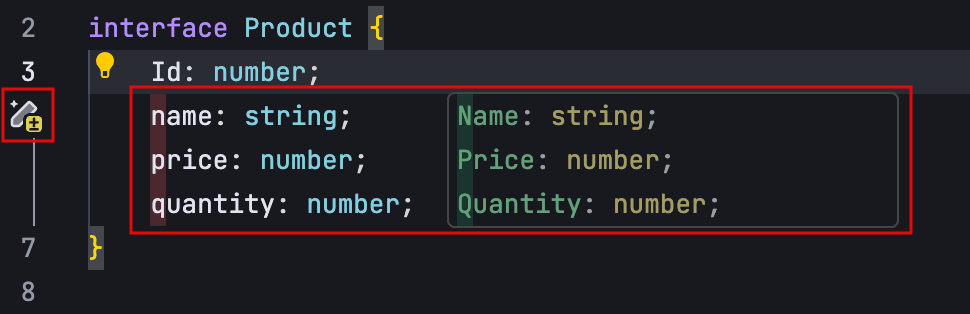
- 修改点预测:通过分析最近的代码修改、浏览记录、Linter 错误等信息,并结合当前仓库的内容,自动预测未来可能的修改点。
在以下示例中,代码定义了四个并列字段:id、name、price 和 quantity。当将 id 字段的首字母改为大写时,AI 会识别这一修改行为,并提示用户将 name、price 和 quantity 字段的首字母也一并改为大写。
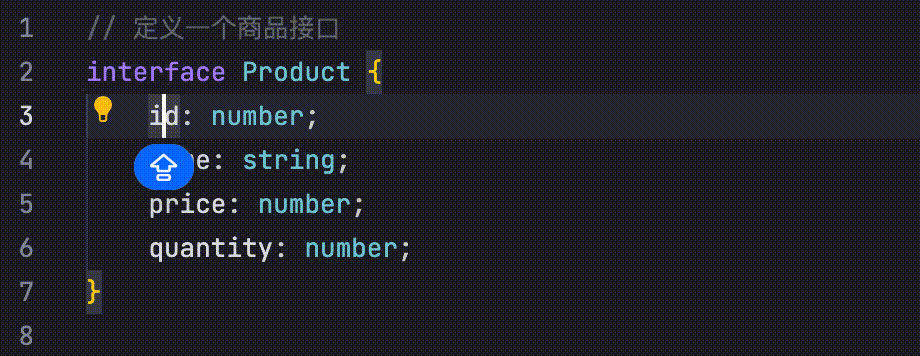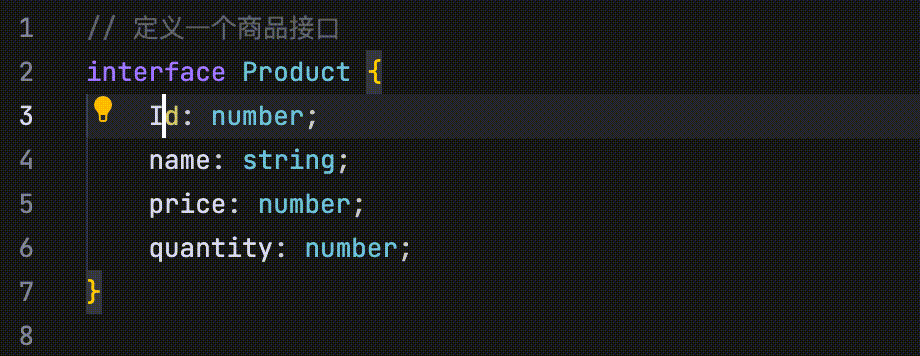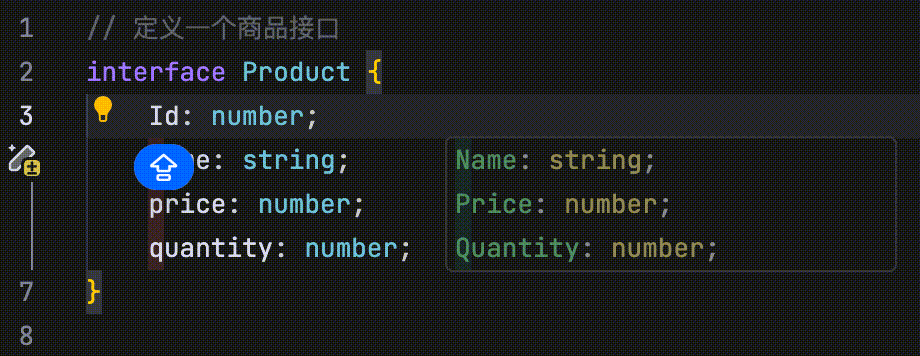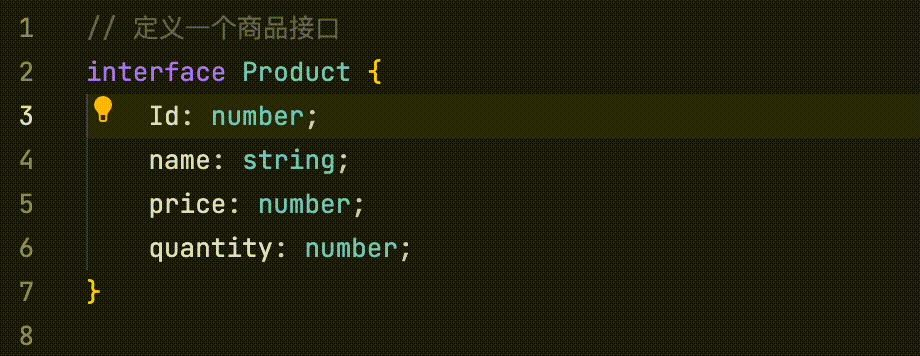
- 修改点跳转:当你修改代码(如函数或字段名称等)后,AI 会自动引导你跳转到与该修改相关的其他位置。
在以下示例中,将 id 字段的首字母改为大写后,编辑器中 id 字段所在的其他位置会显示“Jump Here”字样,提示你可以跳转至该位置完成相关修改。
UI 说明
自动补全的代码在编辑器内以灰色字体呈现,且左侧会显示绿色的 “建议增加代码” 图标进行提示。
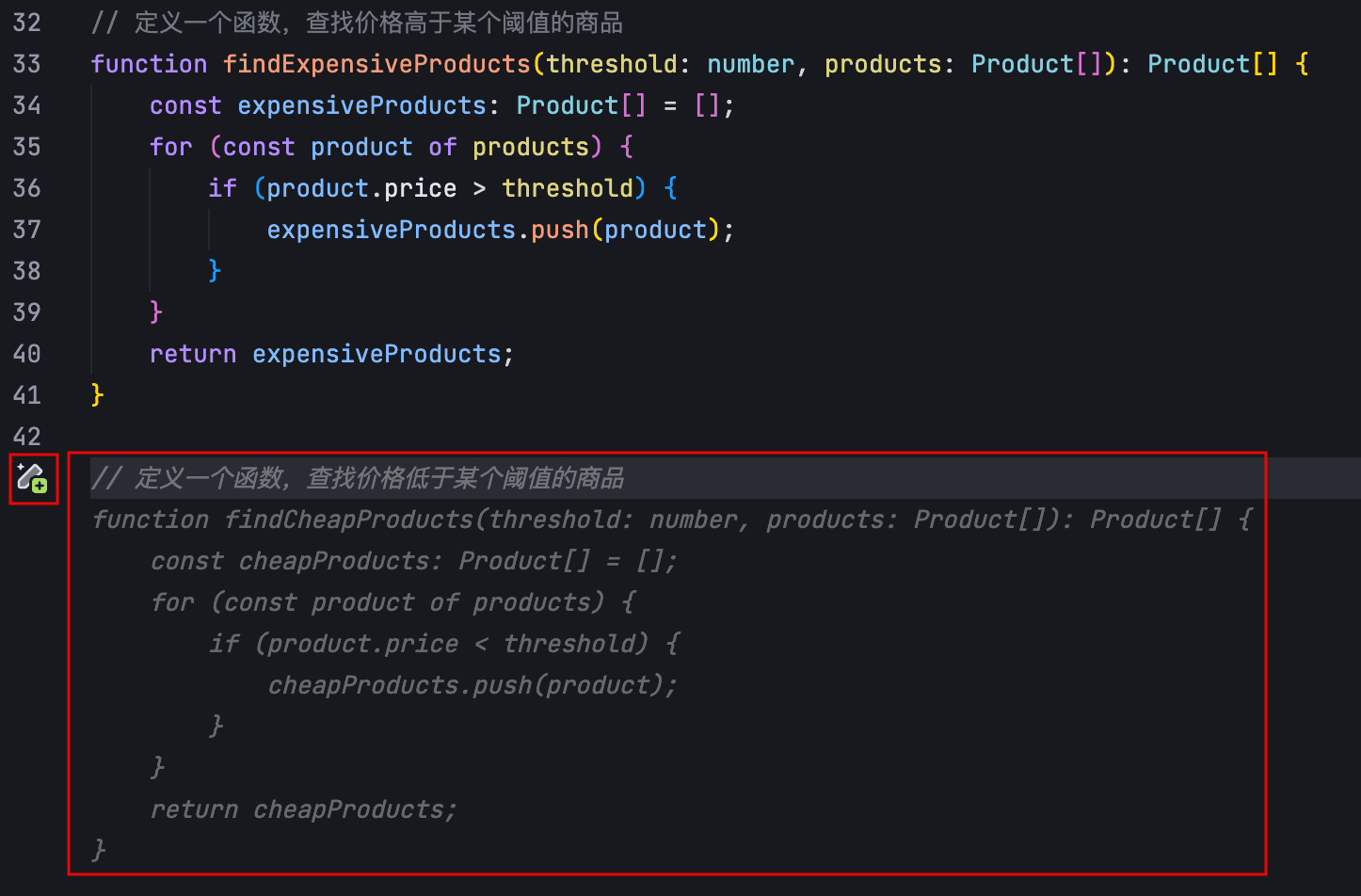
涉及多个代码行的修改时,编辑器内以 diff 形式展示修改内容,且左侧会显示黄色的 “建议修改代码” 图标进行提示。
引导你跳转至相关修改点时,修改点位置附近会出现 Jump Here 字样,且该行代码左侧会显示紫色的 “建议修改” 图标进行提示。按下 Tab 键后可跳转至该修改点。

快捷键
使用快捷键来接受或拒绝建议的修改。
- 按下 Tab 键,一次性接受一个建议的修改,或使用 Ctrl / Command + → 组合键逐字接受一个建议的修改。
- 按下 Escape 键拒绝一个建议的修改;或继续编写代码,以忽略建议的修改。
17.3.6 对话
1、侧边对话
编码过程中,你可以随时在侧边对话框中与 AI 助手对话,包括回答编码问题、讲解代码仓库、生成代码片段、修复错误等。
2、行内对话
Trae 提供了内嵌在代码编辑器中的行内对话(Inline Chat)。你能够在编码的过程中随时唤起行内对话。使用行内对话可以让你在与 AI 助手对话的同时更好地保持编码心流。
你可以通过以下两种方式唤起行内对话:
- 在编辑器内的光标处,使用快捷键(macOS:Command + I;Windows:Ctrl + I)。
- 在编辑器内,选中任意代码,然后使用快捷键(macOS:Command + I;Windows:Ctrl + I)或点击悬浮菜单中的 编辑 按钮。
开始问答
在行内对话输入框中输入你的需求,包括为代码添加注释、解释选中的代码、优化选中的代码等等,然后点击右侧的 发送 按钮或敲击回车键。
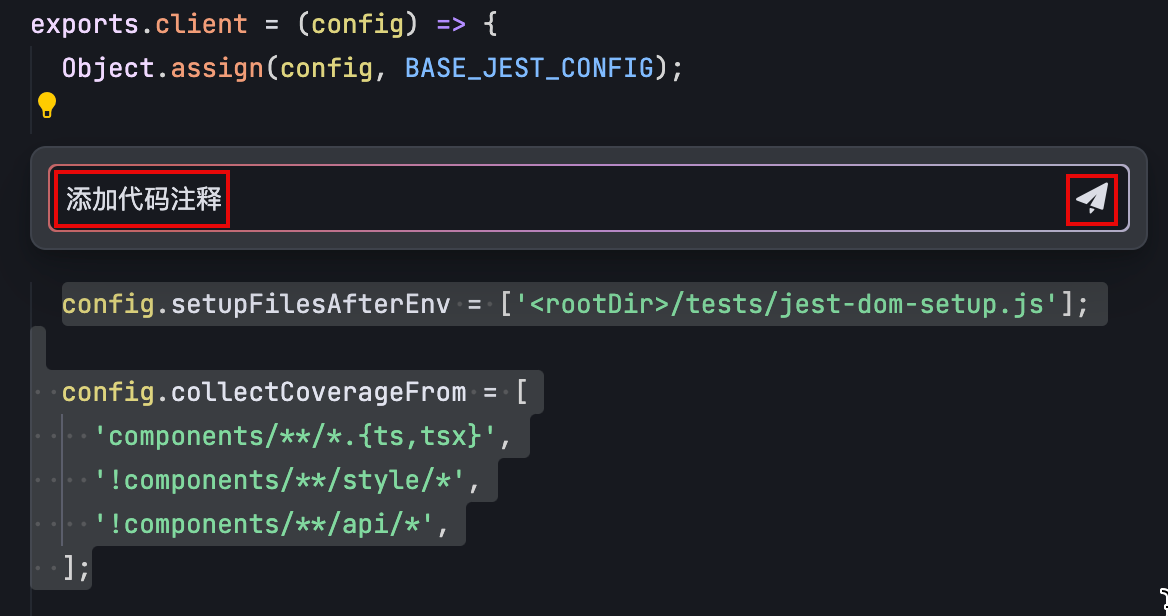
处理结果
发送需求后,AI 助手生成的内容将以 Diff 的形式展示在编辑器内。你可以预览变更前后的代码,然后选择采纳或拒绝。
- 若你需要接受或拒绝所有内容,点击对话框左下角的 接受 按钮(快捷键:macOS 为 Command + Enter;Windows 为 Ctrl + Enter)或 拒绝 按钮(快捷键:macOS 为 Command + Backspace;Windows 为 Ctrl + Backspace)按钮。
- 若你需要接受或拒绝部分内容,点击内容片段右上角的 ^Y 按钮(快捷键:macOS 为 Control + Y;Windows 为 Alt + Y)或 ^N 按钮(快捷键:macOS 为 Control + N;Windows 为 Alt + N)。
17.3.7 模型
Trae 预置了一系列业内表现比较出色的模型,你可以直接切换不同的模型进行使用。此外,Trae 还支持通过 API 密钥(API Key)接入自定义模型,从而满足个性化的需求。
切换模型
在 AI 对话输入框的右下角,点击当前模型名称,打开模型列表,然后选择你想使用的模型。各个模型的能力不同,你可以将鼠标悬浮至模型名称上,然后查看该模型支持的能力。
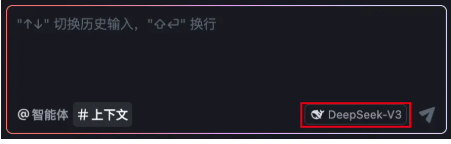
添加自定义模型
如果你希望使用预置模型之外的其它模型,或者想使用自己的模型资源,则可以通过 API 密钥连接你自己的模型资源或其他第三方模型服务商。
- 在 AI 对话框右上角,点击 设置 图标 > 模型,
- 点击 + 添加模型 按钮。
选择 服务商。可选项有:Anthropic、DeepSeek、OpenRouter、火山引擎、硅基流动、阿里云、腾讯云、模力方舟、BytePlus、Gemini。
选择 模型:
直接从列表中选择 Trae 为每个服务商预置的模型(均为默认版本)。
若你希望使用其他模型或使用特定版本的模型,点击列表中的 使用其他模型,然后在输入框中填写模型 ID。
填写 API 密钥。
Trae 将调用服务商的接口来检测 API 密钥是否有效。可能的结果如下:
若连接成功,该自定义模型会被添加。
若连接失败,添加模型 窗口中展示错误信息和服务商返回的错误日志,你可以参考这些信息排查问题。
17.3.8 智能体
智能体(Agent)是你面向不同开发场景的编程助手。
智能体的能力
自主运行 - 独立探索你的代码库,识别相关文件并进行必要修改。
完整的工具访问权限 - 使用所有可用工具进行搜索、编辑、创建文件及运行终端命令。
上下文理解 - 建立对你项目的结构和依赖关系的全面理解。
多步骤规划 - 将复杂任务拆分为可执行的步骤,并按顺序逐一处理。
智能体的工作流
需求分析:深入理解任务目标及代码库上下文,明确需求要点。
代码调研:检索代码库、文档及网络资源,定位相关文件并分析现有实现逻辑。
方案设计:根据分析结果拆解任务步骤,并动态优化调整修改策略。
实施变更:照计划在整个代码库中进行必要的代码变更,过程中可能涉及:
新增依赖库推荐
按需执行的终端指令
Trae IDE 客户端外的手动操作指引
交付验收:完成验证后移交控制权,同步汇总所有修改内容。
内置智能体
Trae IDE 提供以下内置智能体:
Builder:Builder 可以帮助你从 0 到 1 开发一个完整的项目。根据你的需求,Builder 会调用不同的工具,包括分析代码文件的工具、编辑代码文件的工具、运行命令的工具等等,从而更加精确且有效地处理你的需求。
Builder with MCP:在 Builder 的基础上,你配置的所有 MCP Server 都会默认添加至 Builder with MCP,且不可编辑。
创建自定义智能体(略)
同时,你还可以创建自定义智能体,通过灵活配置提示词和工具集,使其更高效地帮你完成复杂任务,比如创建专门负责页面设计和前端开发的网页设计智能体,以及需求文档撰写智能体、代码调研智能体、任务规划智能体等。
17.3.9 上下文
与 AI 助手对话时,你可以指定上下文供 AI 助手阅读和理解,使 AI 助手的答复更精准。
1、将编辑器内的内容作为上下文
当你的编辑器中存在正在编辑的代码文件时,AI 助手默认能够看到当前文件。你可以直接向 AI 助手提问与当前文件相关的问题。若期望对文件中的某一段代码进行提问,使用以下步骤:
- 选中代码。
- 点击悬浮菜单中的 添加到对话 按钮,将选中的内容作为上下文添加至侧边对话框。
指定的上下文会显示在侧边对话底部的输入框。以下图为例,输入框内显示所选内容所属的文件名称,以及所选的代码行编号。

- (可选) 继续添加编辑器中的其他内容片段,或同时添加其他来源的上下文。
2、将终端中的内容作为上下文
若你希望对终端中的输出内容进行提问(如帮助你修复报错),使用以下步骤:
- 在终端中,点击输出内容片段。
- 在内容片段区域的右上角,点击 添加到对话 按钮,将选中的内容作为上下文添加至侧边对话框。
指定的上下文会显示在侧边对话底部的输入框。以下图为例,输入框内显示上下文的来源以及行号。
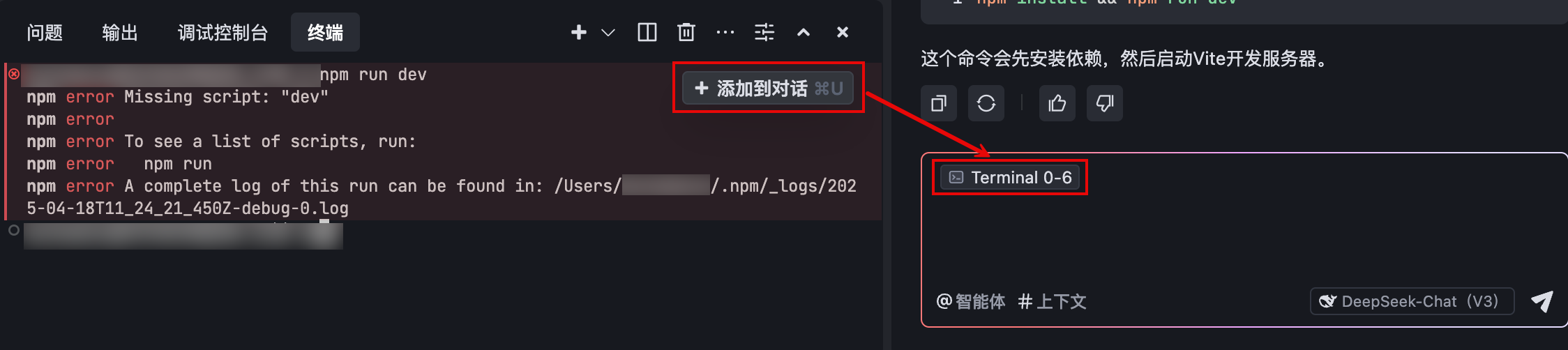
- (可选) 继续添加终端中的其他内容片段,或同时添加其他来源的上下文。
3、使用 # 符号添加上下文
在侧边对话的输入框中,你可以通过 # 符号添加多种类的上下文,包括代码、文件、文件夹、代码仓库、文档集和网页。通常情况下,列表中将展示与编辑器中当前打开文件相关的内容作为推荐的上下文,但你仍然可以自行搜索所需的上下文并将其添加到输入框中。
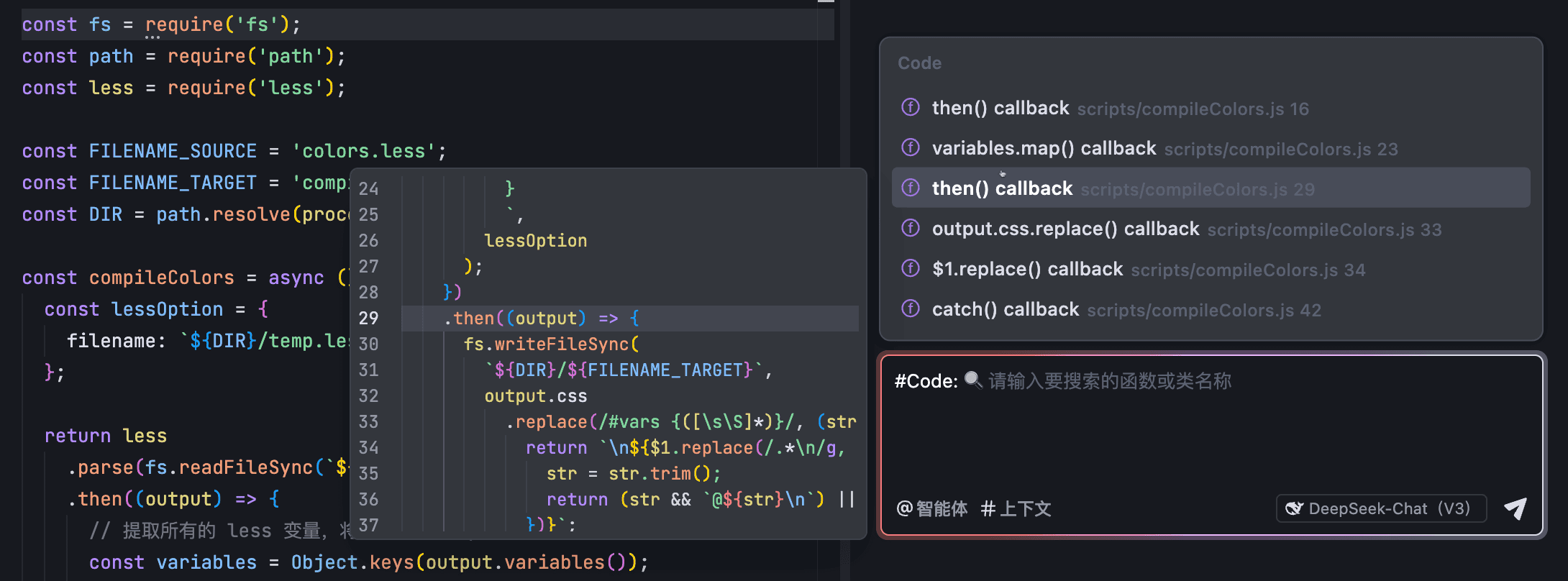
#Code
通过 #Code,你可以将函数或类的相关代码作为与 AI 助手对话的上下文。列表中默认展示当前编辑器内打开的文件中的函数或类。选择前,你可以预览列表中推荐的函数或类的相关代码。若推荐的内容非你所需,你可以通过关键词搜索所需的函数或类。
若 Trae 中不存在对应语言的语言服务协议(Language Server Protocol),请提前安装,否则可能导致无法识别代码符号。
在输入框中输入 #,或直接点击输入框左下角的 # 上下文 按钮。输入框上方显示上下文类型选择列表。
在列表中选择 Code(或在 # 符号后手动输入 Code),然后按下回车键。
列表将展示编辑器中当前打开的文件中存在的函数和类。将鼠标悬浮在列表中的某个条目后,左侧会展示该函数或类的代码内容,供你预览。
- 若推荐的函数和类非你所需,在 #Code: 后输入你想要的函数或类的名称或关键词。
AI 助手将在项目内搜索相关函数和类,并展示在列表中,你可以进行预览。
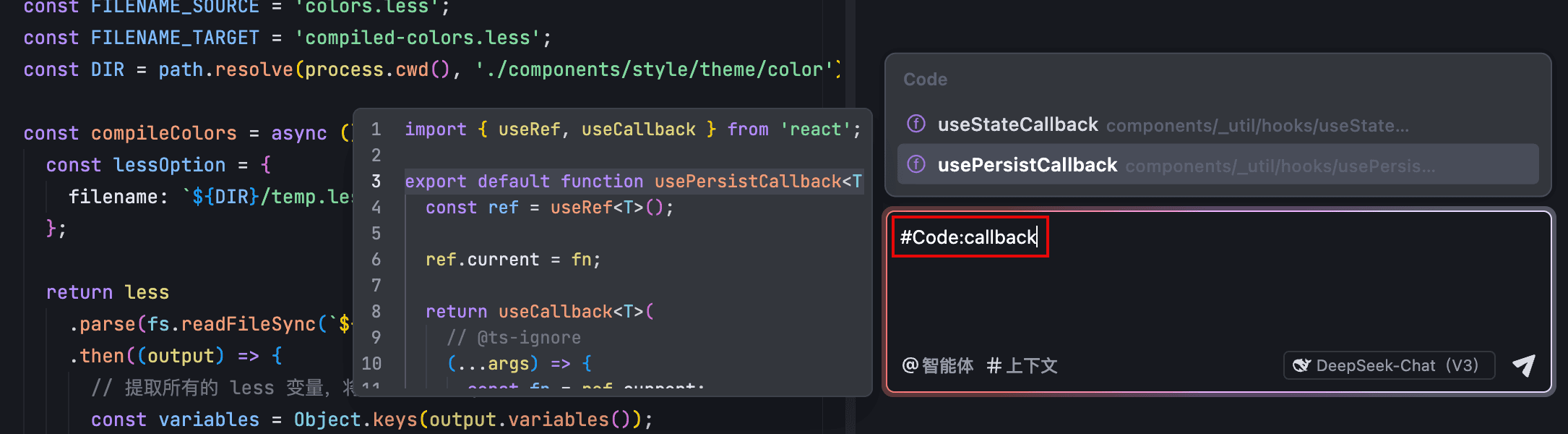
- 从列表中选择需指定为上下文的函数或类。
#File
通过 #File,你可以将指定文件中的所有内容作为与 AI 助手对话的上下文。列表中默认展示近期在编辑器中打开过的文件。你可以预览这些文件所在的目录,以免因存在同名文件而导致错选。若展示的文件非你所需,你可以通过关键词搜索所需文件。
在输入框中输入 #,或直接点击输入框左下角的 # 上下文 按钮。
在列表中选择 File(或在 # 符号后手动输入 File),然后按下回车键。
列表展示近期在编辑器中打开过的文件。将鼠标悬浮在列表中的某个条目后,左侧会展示该文件所在的目录。
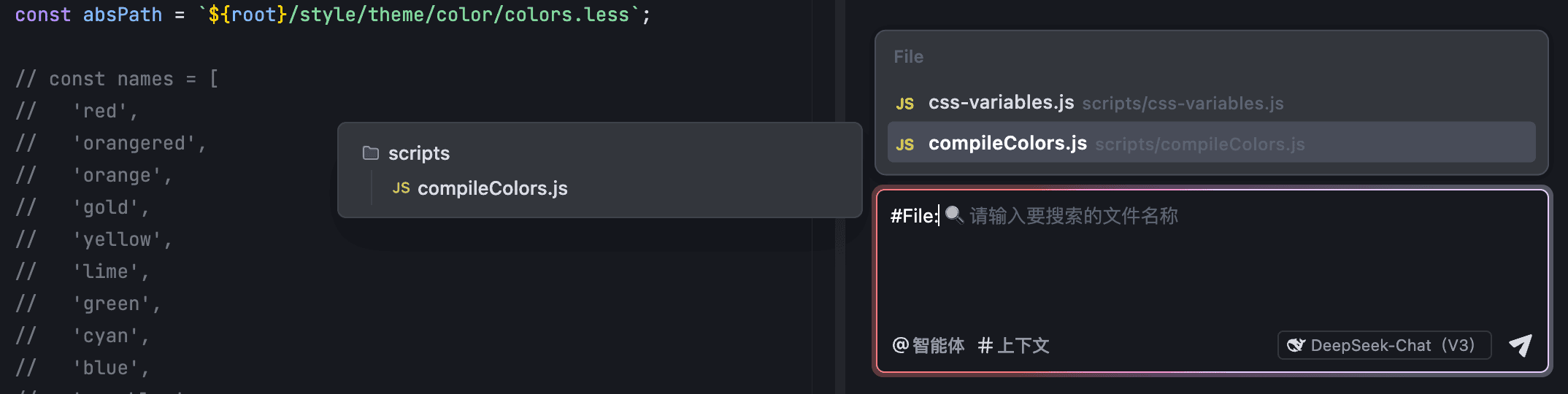
- 若推荐的文件非你所需,在 #File: 后输入你想要的文件的名称或关键词。
AI 助手将在项目内搜索相关文件并展示在列表中。
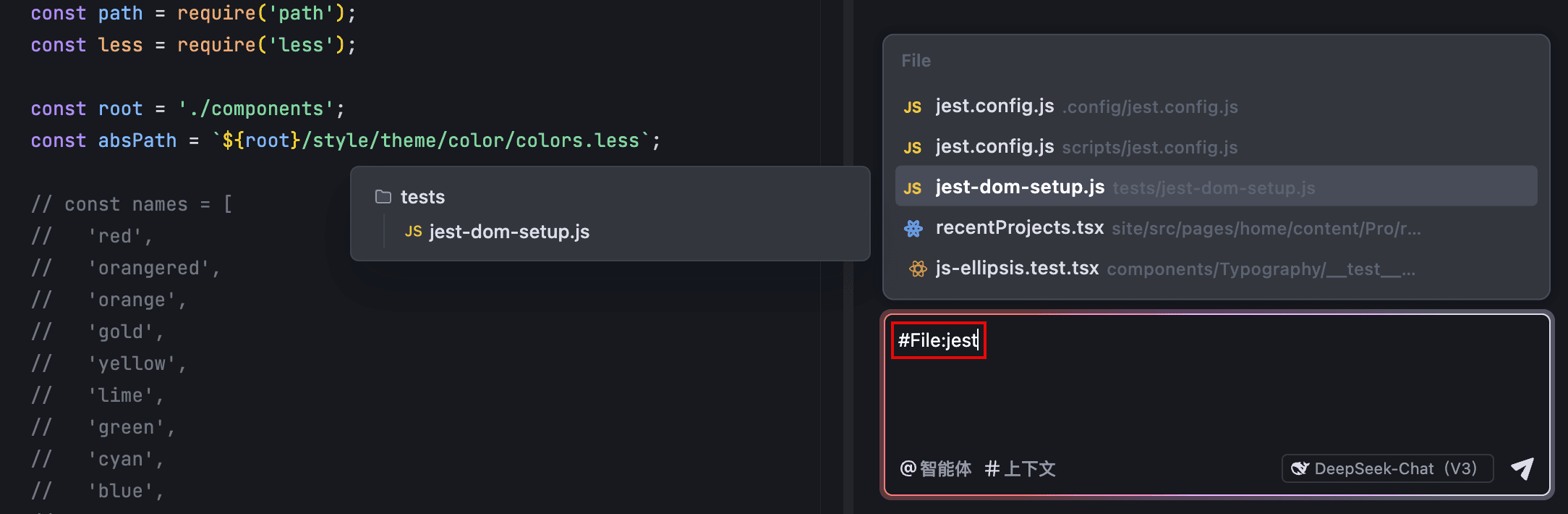
- 从列表中选择需指定为上下文的文件。
#Folder
通过 #Folder,你可以将指定文件夹中的所有内容作为与 AI 助手对话的上下文。列表中默认展示与编辑器中当前所打开文件相关的文件夹。你可以预览这些文件夹所在的目录,以免因存在同名文件夹而导致错选。若展示的文件夹非你所需,你可以通过关键词搜索所需文件夹。
#Folder 依赖项目代码索引(Project Code Index)是否构建完全。若索引暂未构建完全,可能会影响文件夹内容召回的效果,从而导致 AI 助手的回答不够完整。提问时,若索引从未构建或正在构建中,References 位置将出现 “索引构建中” 或 “索引暂未构建” 的提示,你可以根据引导在设置页管理索引。详情参考《AI 设置》。
在输入框中输入 #,或直接点击输入框左下角的 # 上下文 按钮。
在列表中选择 Folder(或在 # 符号后手动输入 Folder),然后按下回车键。
列表展示与编辑器中当前所打开文件相关的文件夹。将鼠标悬浮在列表中的某个条目后,左侧会展示该文件夹所在的目录。
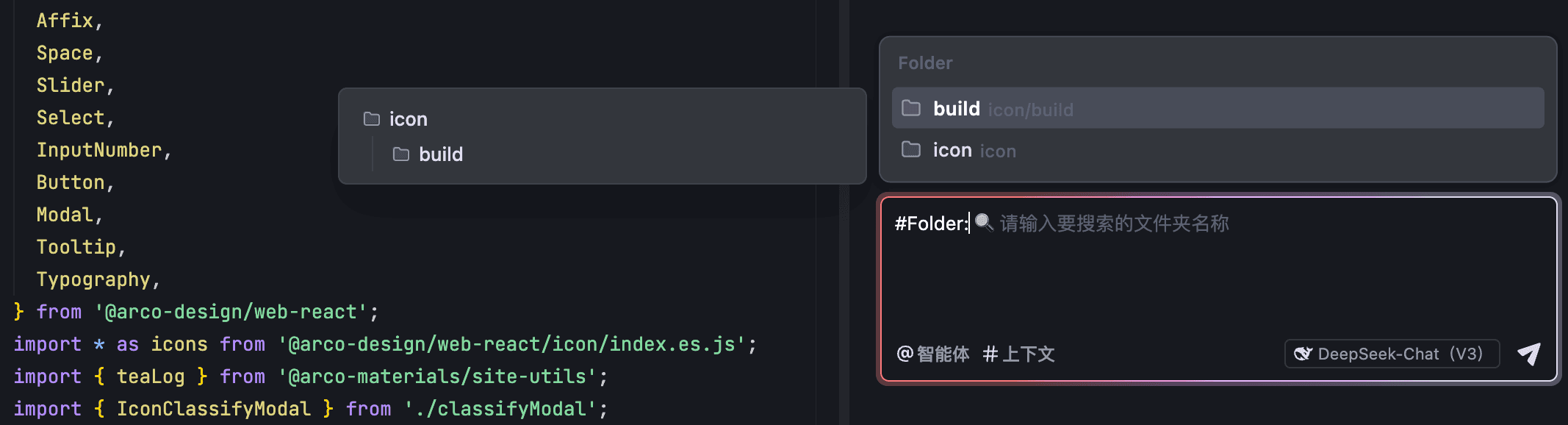
- 若推荐的文件夹非你所需,在 #Folder: 后输入你想要的文件夹的名称或关键词。
AI 助手将在项目内搜索相关文件夹并展示在列表中。
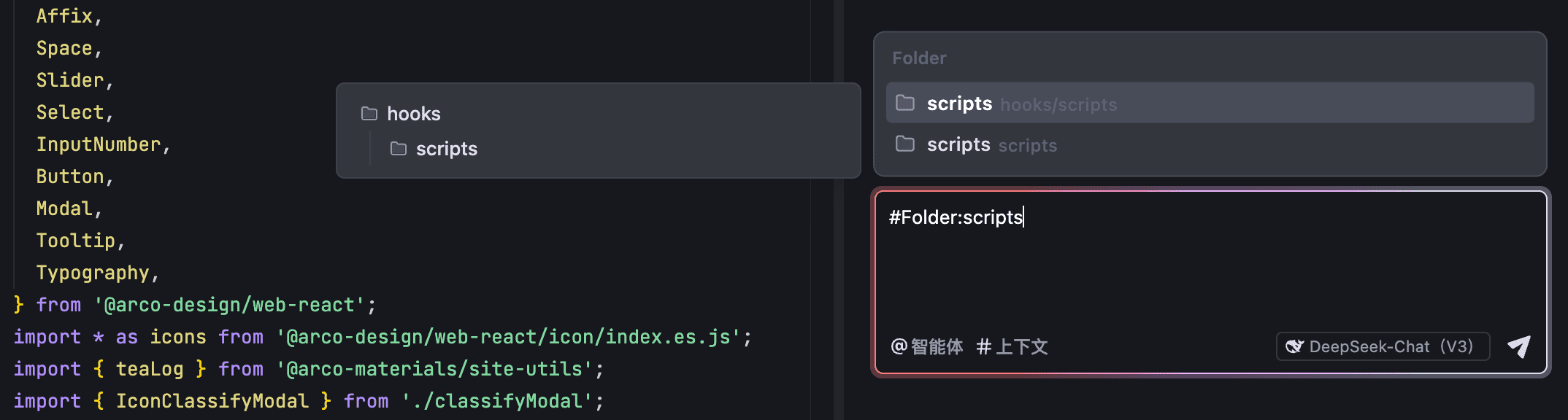
- 从列表中选择需指定为上下文的文件夹。
#Workspace
你可以使用 #Workspace 来向 AI 助手提出有关整个工作空间的问题,AI 助手将自动在工作空间中查找与你的问题最相关的内容作为上下文进行回答。遇到不熟悉的项目时,该功能可以帮助你全局了解该项目所实现的功能和代码,从而使你快速上手该项目的开发。
- 仅支持在 Chat 模式中使用。Builder 模式会自动将整个工作空间作为上下文。
- #Workspace 依赖项目代码索引(Project Code Index)是否构建完全。若索引暂未构建完全,可能会影响文件夹内容召回的效果,从而导致 AI 助手的回答不够完整。提问时,若索引从未构建或正在构建中,References 位置将出现 “索引构建中” 或 “索引暂未构建” 的提示,你可以根据引导在设置页管理索引
#Doc
你可以上传个人文档集,将文档内容作为 AI 对话的上下文**,**让 AI 更精准地处理你的需求。
创建文档集时,Trae 将针对文档集内容构建索引,在索引过程中文档数据将被传输至 Trae 服务器进行矢量化,但 Trae 不会读取或存储任何文档数据,矢量化完成后文档数据和矢量数据都将从 Trae 的服务器中删除,数据将返回至用户的设备并存储在用户本地。在 Trae 中删除文档集后,本地数据也将被同步删除。
创建文档集并将其引用为上下文的步骤如下:
- 在 AI 对话窗口的右上角,点击 设置 图标 > 上下文,或在 AI 对话输入框中点击 # 上下文 > Doc > 添加文档集。
- 在 文档集 部分,点击 + 添加文档集 按钮。
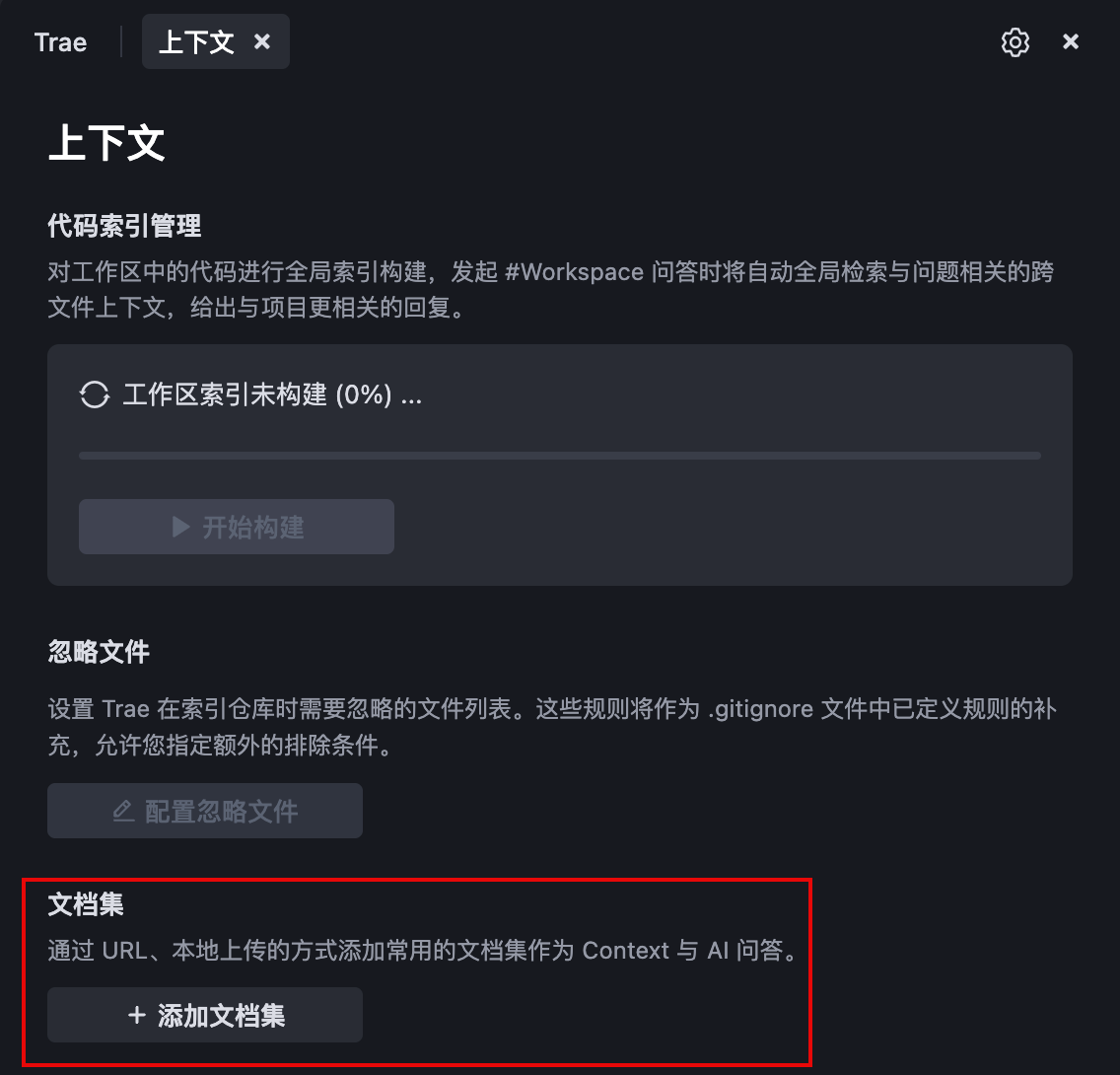 3. 选择合适的方式添加文档集。
3. 选择合适的方式添加文档集。
可以通过 URL 添加,或者本地上传方式添加:
(1)在菜单中选择 通过 URL 添加 选项,然后在弹窗中输入文档集名称和文档站的 URL。
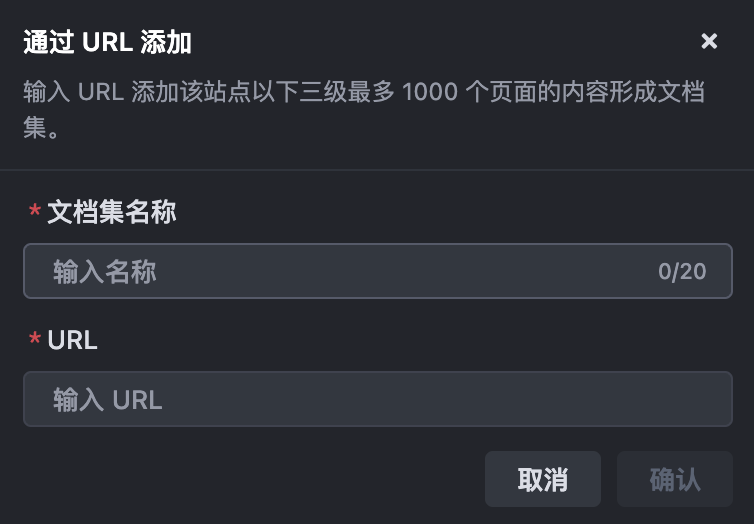
点击 确认 按钮后,Trae IDE 开始索引站点下的网页。以该入口 URL 为起点,Trae IDE 会自动抓取同一站点中与入口 URL 同级路径或子路径下,最多三次跳转内的页面内容。若入口 URL 为 https://www.example.com/docs/api,则:
- 可抓取内容的路径示例如下:
- 不可抓取内容路径示例如下:
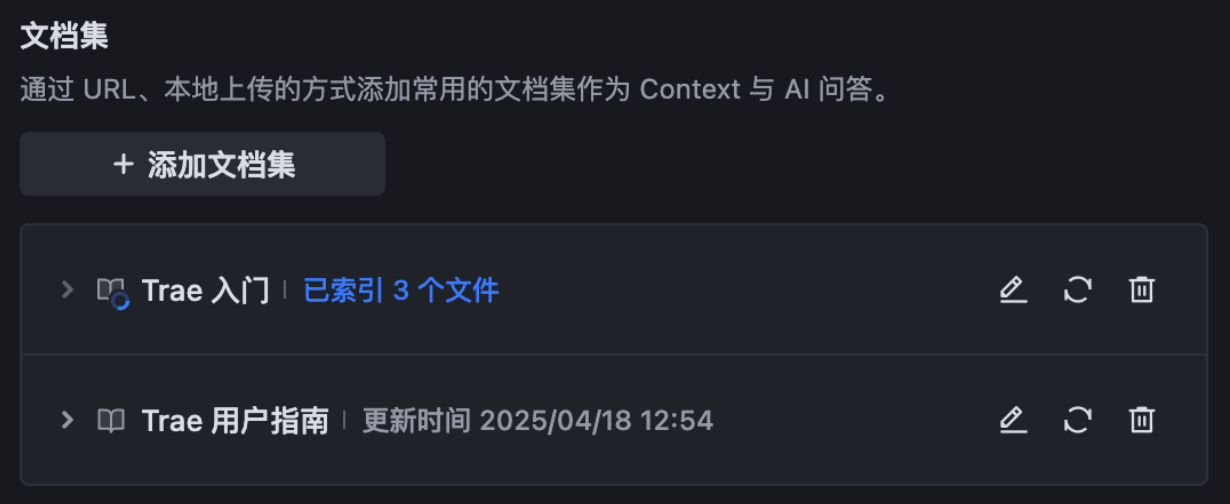
(2)在菜单中选择 从本地文件添加 选项,然后在弹窗中输入文档集名称并添加本地文件。
- 文件格式:.md 和 .txt
- 文件大小:单个文件最大 10 MB
- 文档集大小:最大 50 MB
- 文件数量:不超过 1000 个
点击 确认 按钮后,Trae IDE 开始索引文件。
- 在 AI 对话输入框中,引用你添加的文档集作为上下文。
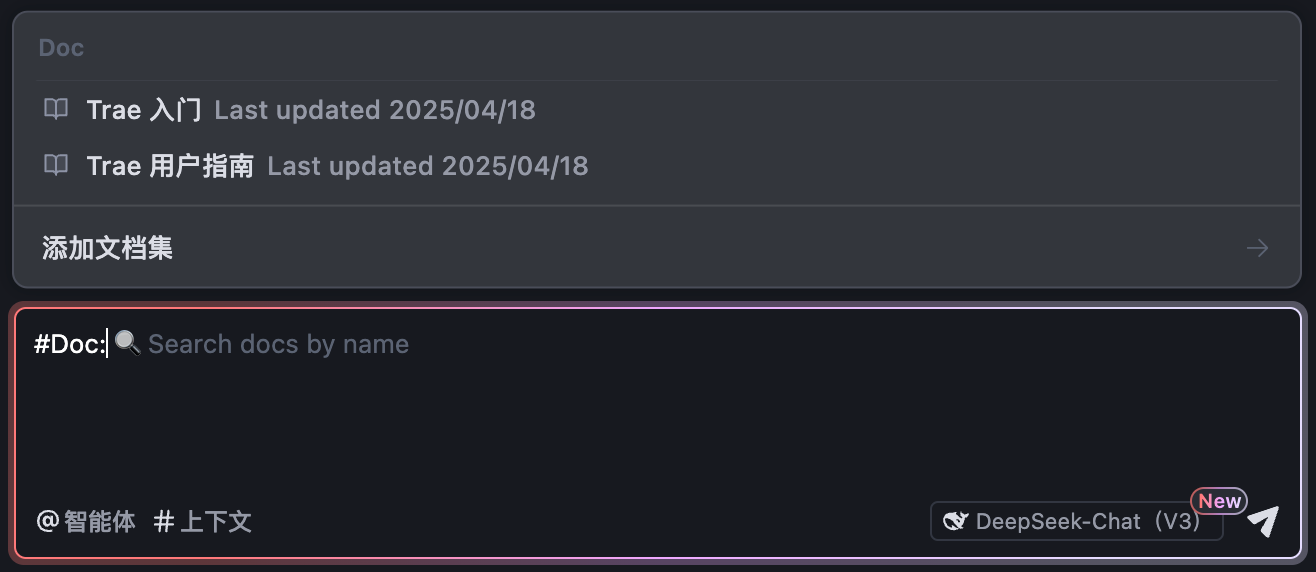
#Web
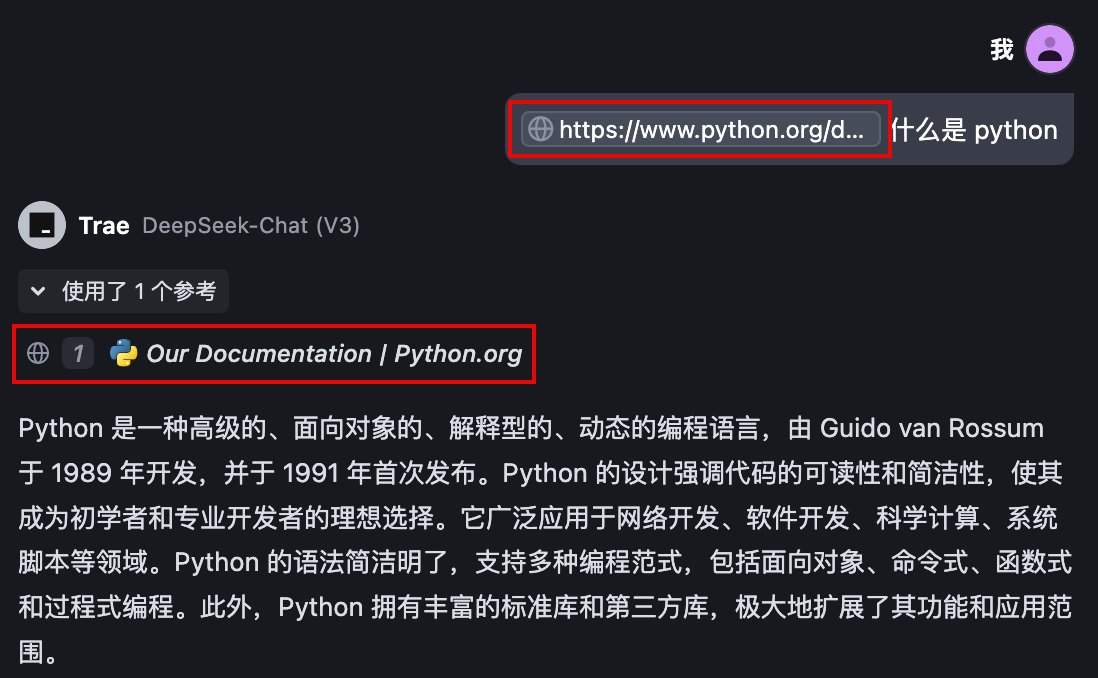
你可以将线上网站的内容作为 AI 对话的上下文。
- 直接在 #Web 后输入你的问题并发送。这种方式会触发联网搜索,Trae AI 会在全网搜索与提问相关的内容并生成答复。
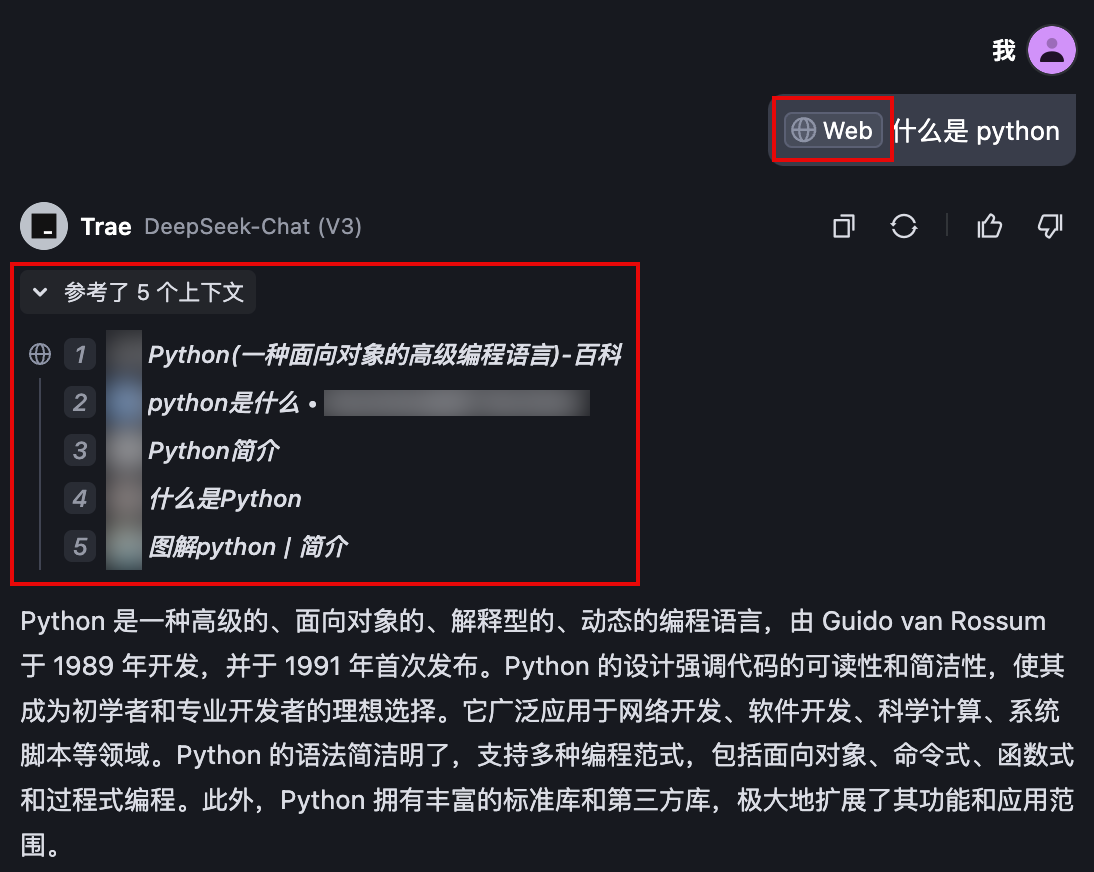
- 在输入框中先输入网址,再输入问题,Trae AI 会直接从该网站查询相关内容并生成回答。这种方式不仅能获取网站的最新信息作为问答依据,还能同时从多个网站检索与问题最相关的内容。
17.3.10 功能演示
提示词 1:
我是一个Java初学者,基于JDK17帮我实现一个客户管理系统。
(1)只用数组,不要用集合、数据库
(2)分为com.atguigu.bean、
com.atguigu.service、
com.atguigu.view、
com.atguigu.main包,主类放到main包中
(3)基于文本界面实现提示词 2:
我是一个Java初学者,基于JDK17帮我实现一个客户管理系统。
(1)可以用集合,但是不用数据库
(2)分为com.atguigu.bean、
com.atguigu.service、
com.atguigu.view、
com.atguigu.main包,主类放到main包中
(3)基于文本界面实现
(4)可以使用maven,依赖lombok17.4 AI 大模型
17.4.1 国际主流 AI 大模型
- OpenAI GPT-4o(GPT-5 系列)
- 特点:参数规模突破 10 万亿,支持多模态输入(文本、图像、音频、视频),推理能力接近人类水平,在复杂逻辑和跨领域知识整合中表现突出。
- 应用场景:科研分析、跨行业决策支持、全媒体内容生成。
- 优势:技术领先,生态完善;劣势:商业化程度高,部分功能收费。
- Google Gemini 2.0 Ultra
- 特点:原生多模态架构,支持 100+语言实时互译,深度集成 Google 生态(搜索、办公套件),上下文窗口扩展至 200 万 token。
- 应用场景:全球化企业协作、实时翻译、多模态搜索引擎优化。
- Anthropic Claude 3.5-Sonnet(Anthropic)
- 特点:200K~1M tokens 上下文窗口,宪法 AI 架构确保合规性,医疗和法律领域表现卓越。
- 应用场景:法律文书分析、医疗诊断辅助、高安全性对话系统。
- Meta LLaMA-3(Facebook)
- 特点:开源 700 亿参数模型,推理速度提升 200%,在开源社区中性能接近 GPT-4。
- 应用场景:中小企业定制化 AI 解决方案、学术研究。
- Falcon-200B(阿联酋 TII)
- 特点:1800 亿参数开源模型,数学推理和代码生成能力对标 GPT-4,训练成本仅为同类模型的 1/3。
17.4.2 国内主流 AI 大模型
- DeepSeek-V3(深度求索)
- 特点:文科能力(78.2 分)超越多数国际竞品,理科(72.0 分)均衡,API 服务模式适合开发者集成。
- 优势:低成本训练(仅 600 万美元),推理效率高。
- 通义千问(Qwen2.5-Max,阿里巴巴)
- 特点:中文理解全球领先,数学和编程能力单项第一,支持百万级上下文窗口和多模态交互。
- 优势:全尺寸开源(7B~110B 参数),Hugging Face 开源生态排名第一。
- 文心一言 4.0(百度)
- 特点:深度整合百度知识图谱,在医疗、教育、金融等领域应用广泛,日均调用量 15 亿次。
- 豆包 1.5-Pro(字节跳动)
- 特点:稀疏 MoE 架构,训练成本低但性能等效 7 倍 Dense 模型,擅长语音识别和实时交互。
- 讯飞星火(科大讯飞)
- 特点:语音识别与合成能力行业标杆,支持 30+语言交互,教育场景应用广泛。
- 腾讯混元 TurboS
- 特点:万亿参数规模,支持文本到视频生成,在 Chatbot Arena 排名全球前八。
- 智谱清言 GLM-4(清华大学)
- 特点:国内首个支持视频通话的千亿参数模型,知识问答和创意写作能力均衡。
17.4.3 AI 大模型发展趋势
- 多模态融合(如 GPT-4o、Gemini 2.0 支持文本+图像+视频)。
- 低成本训练与推理优化(如 DeepSeek 的强化学习降低算力依赖)。
- 开源生态崛起(如通义千问、LLaMA-3 推动中小企业和垂直领域应用)。
- 行业专用模型(如百川大模型专精医疗,商汤 SenseChat 优化自然语言生成)。
目前 AI 大模型呈现“中美双强”格局:
- 国际巨头(OpenAI、Google)在技术和生态上领先,但面临监管和数据隐私挑战。
- 中国模型(如 DeepSeek、通义千问)在中文场景和行业应用中表现突出,并通过开源和低成本训练快速追赶。
未来,模型能力的提升将更多依赖算法优化而非单纯参数扩张,同时开源生态和端侧应用或成竞争关键点
17.4.4 AI 大模型编程能力排名
2025 年 7 月全球 AI 大模型编程能力排名中,Claude 3.7 Sonnet 以 91.2 分位列榜首,DeepSeek R1 和通义千问 Qwen2.5-Max 分别代表国际与国内顶尖水平。
全球编程能力排名及关键指标
- Claude 3.7 Sonnet(Anthropic)
- HumanEval 评测得分 91.2 分,支持 10 万 token 长文档解析,代码生成能力断层领先。
- DeepSeek R1(深度求索)
- 国产开源模型代表,中文长文本处理专家,ReLE 评测编程得分 87.7%,推理速度提升 3 倍。
- 通义千问 Qwen2.5-Max(阿里云)
- Chatbot Arena 全球编程单项第一,多模态融合任务支持全栈开发(通义灵码)。
- GPT-4.5(OpenAI)
- 综合理科能力得分 87.3 分,支持 32K 上下文,代码生成能力保持国际第一梯队。
- Gemini 2.0(Google)
- 原生多模态架构标杆,百万级上下文窗口适配工业级代码开发。
细分领域优势对比
- 开源模型性价比:DeepSeek R1 训练成本仅为 OpenAI 同类模型的 1/27,开发者可直接调用 API 或部署私有化版本。
- 多模态编程支持:通义千问 Qwen2.5-Omni-7B 支持文本、图像、音频、视频全模态交互,适合复杂任务处理。
- 企业级应用:百度文心一言 4.0 中文场景优化领先,已服务 8 万企业用户,适配标准化开发需求。
选型建议
- 科研与开发:优先选择 DeepSeek R1(开源生态)或 Claude 3.7 Sonnet(顶尖性能)。
- 多模态集成:通义千问 Qwen2.5-Max 提供全栈工具链,支持 AI 全生命周期开发。
- 成本敏感场景:开源模型(如 DeepSeek-V3、Qwen2.5-Omni-7B)日均调用成本低于商用模型 30%。
17.5 Ollama(选讲)
Ollama 是一个开源的大型语言模型(LLM)本地运行工具,专注于让用户能够轻松地在自己的计算机上部署和运行各种 AI 模型(如 LLaMA、Mistral、Gemma 等),而无需依赖云端服务。
Ollama 核心功能
- 本地运行模型:支持在个人电脑(macOS、Linux、Windows)上离线运行 LLM,保护隐私且减少网络依赖。
- 多模型支持:提供丰富的预训练模型,包括: DeepSeek-R1, Qwen 3, Llama 3.3, Qwen 2.5‑VL, Gemma 3, and other models
- 简化部署:通过命令行一键下载、运行模型,无需复杂配置。
- 类 OpenAI API:兼容 OpenAI 的 API 格式,方便开发者集成到现有工具中。
类似的工具对比:
- LM Studio:更友好的 GUI,但仅限 Windows/macOS。
- GPT4All:专注开源模型,界面简单。
- Text Generation WebUI:功能更复杂,适合高级用户。
17.5.1 下载和安装
下载官网:https://ollama.com/
如果直接双击 安装无法设置安装路径。建议用如下方式安装,进入安装包所在目录的命令行,然后运行:
安装无法设置安装路径。建议用如下方式安装,进入安装包所在目录的命令行,然后运行:
安装包程序名称 /dir=安装路径例如:
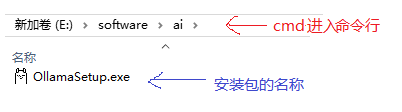
OllamaSetup.exe /dir=D:\ProgramFiles\Ollama
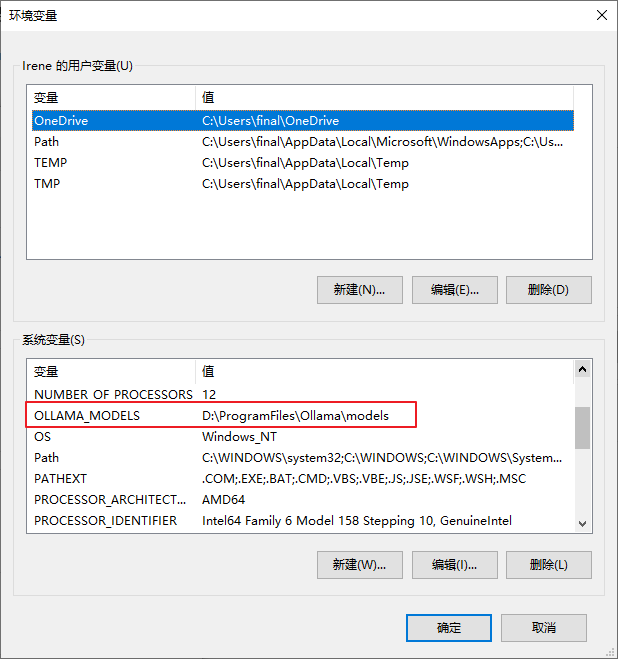
17.5.2 配置环境变量
环境变量名:OLLAMA_MODELS
环境变量值:Ollama 本地模型存储路径
17.5.3 常用命令
查看已下载的本地模型:
ollama list运行某个本地模型:
ollama run 模型名如果这个模型名在本地未下载,会先下载模型然后运行。
可以在 https://ollama.com/search 查看具体的模型名。
删除某个本地模型:
ollama rm 模型名更多的命令请看:
ollama -h17.6 部分术语解释
17.6.1 AI 模型的参数量和数据规模
参数量(Parameters)是指模型内部可调整的权重数量,即模型结构的复杂度。例如:
| 模型 | 架构 | 总参数 | 激活参数 |
|---|---|---|---|
| DeepSeek-MoE-16b | MoE(稀松) | ~100B? | 16B |
| DeepSeek-V3 | Dense(稠密) | ~100B+ | 100B+ |
| GPT-3.5 | Dense | 175B | 175B |
| Mixtral-8x7B | MoE | 56B | 12.9B |
数据规模(Data Size)是指训练模型时使用的数据总量(如文本 Token 数、图像数量等)。例如:
| 维度 | DeepSeek-MoE-16b | DeepSeek-V3 |
|---|---|---|
| 数据量 | 可能相对较小(如 1T+ Token) | 可能更大(如 3T+ Token) |
| 数据多样性 | 侧重通用领域+高效学习 | 更全面覆盖(代码、学术、多语言等) |
| 数据质量筛选 | 严格过滤,适配稀疏模型的高效训练 | 更注重广度,支持稠密模型深度学习 |
- Hundred(百)—— 100
- Thousand(千)—— 1,000
- Million(百万)—— 1,000,000
- Billion(十亿)—— 1,000,000,000(美式英语)
- Trillion(万亿)—— 1,000,000,000,000
- Quadrillion(千万亿)—— 1,000,000,000,000,000
- Quintillion(百亿亿)—— 1,000,000,000,000,000,000
17.6.2 Token
1、什么是 Token?
在自然语言处理(NLP)和大语言模型(如 GPT、Claude)中,Token 是文本处理的基本单位,可以理解为模型“读取”和“生成”文字时的最小片段。它可以是一个单词、一个子词(subword),甚至是一个字符,具体取决于模型的分词方式(Tokenization)。Token 的常见形式:
(1) 英文 Token
- 完整单词:例如
"hello"、"world"各算 1 个 token。 - 子词(Subword):
"unhappiness"→"un" + "happiness"(2 tokens)"ChatGPT"→"Chat" + "G" + "PT"(3 tokens)- 常用词可能完整保留,罕见词会被拆分。
(2) 中文 Token
- 单字:如
"你好"→"你" + "好"(2 tokens)。 - 词组:部分模型会合并常见词组,如
"人工智能"可能算 1 token(取决于分词器)。 - 标点符号:
,。!?等通常各算 1 token。
(3) 代码 Token
- 变量名、关键字、符号都可能被拆分,例如:
print("Hello")→["print", "(", "\"", "Hello", "\"", ")"](6 tokens)。
2、为什么 Token 重要?
(1) 影响模型的计算和成本
- 上下文窗口限制:模型能处理的 Token 数量有限(如 GPT-4 支持 128K tokens)。
- API 计费:许多 AI 服务(如 OpenAI、Anthropic)按 Token 数量收费(输入+输出)。
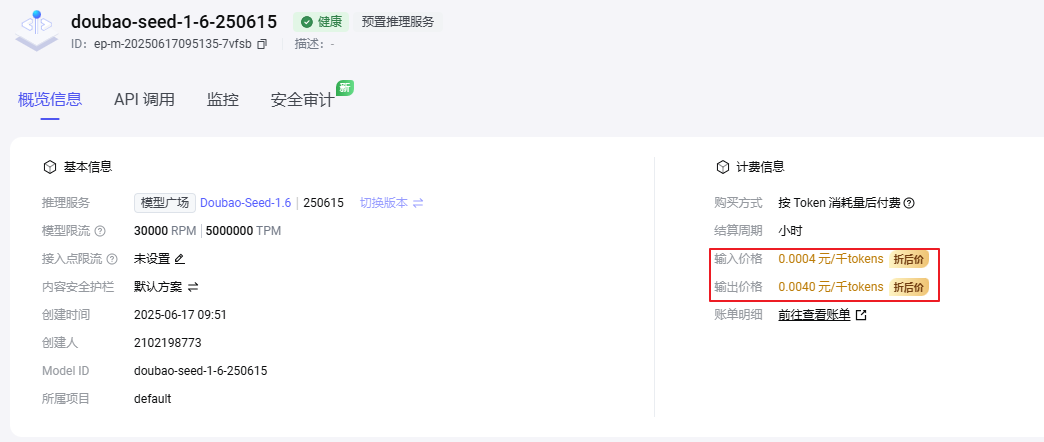
(2) 影响模型的理解能力
- Token 划分方式 影响模型对语义的理解。
- 例如,
"ChatGPT"被拆成"Chat" + "G" + "PT",可能影响模型对缩写词的识别。
- 例如,
3、 如何计算 Token 数量?
(1) 使用官方工具
OpenAI Tokenizer(https://platform.openai.com/tokenizer)
- 输入文本即可查看如何被拆分。
- 例:
"你好,世界!"→ 5 tokens(你、好、,、世界、!)。
火山方舟(https://console.volcengine.com/ark/region:ark+cn-beijing/tokenCalculator)
(2) 估算方法
- 英文:1 token ≈ 4 字符(或 0.75 单词)。
- 中文:1 token ≈ 1~2 个汉字(取决于分词器)。
- 代码:1 token ≈ 2~5 字符(变量名、符号较多)。
17.6.3 使用大模型的常见参数
1. 核心参数
(1) temperature(温度)
- 作用:控制生成文本的随机性和创造性。
temperature=0:模型输出最确定、最保守的答案(适合事实性问答)。temperature=0.7~1.0:平衡创造性和准确性(适合聊天、写作)。temperature>1.0:输出更加随机、可能不连贯(适合诗歌、创意写作)。
(2) top_p(核采样,Nucleus Sampling)
- 作用:从概率最高的单词中采样,避免低质量输出。
top_p=0.9:只考虑概率累计前 90% 的单词(推荐值)。top_p=1.0:无限制,可能生成低概率词(类似temperature调高)。
(3) max_tokens(最大生成长度)
- 作用:限制模型返回的 token 数量(1 token ≈ 1 个英文单词或 2-3 个中文字符)。
- 设置太小 → 回答可能被截断。
- 设置太大 → 可能生成冗余内容。
2. 其他常见参数
(4) frequency_penalty(频率惩罚)
- 作用:降低重复单词的概率(值越大,重复越少)。
frequency_penalty=0:不惩罚重复(默认)。frequency_penalty=1.0:强烈避免重复。
- 适用场景:避免模型重复相同短语。
(5) presence_penalty(存在惩罚)
- 作用:鼓励模型提及新主题(值越大,话题越分散)。
presence_penalty=0:不干预话题(默认)。presence_penalty=1.0:强制引入新内容。
(6) seed(随机种子)
- 作用:固定随机数种子,使相同输入总是得到相同输出(可复现结果)。
3. 参数组合建议
| 场景 | 推荐参数配置 |
|---|---|
| 事实性问答 | temperature=0.2, top_p=0.9 |
| 创意写作 | temperature=0.8, top_p=0.95 |
| 代码生成 | temperature=0.5, max_tokens=1024 |
| 避免重复 | frequency_penalty=0.5 |
4. 如何调参?
- 先固定
temperature和top_p:- 一般
temperature=0.7,top_p=0.9是平衡点。
- 一般
- 调整生成长度
max_tokens:- 短回答:
max_tokens=200 - 长文生成:
max_tokens=1000
- 短回答:
- 解决重复问题:
- 增加
frequency_penalty(如0.5)。
- 增加
- 需要确定性输出:
- 降低
temperature(如0.2)或固定seed。
- 降低
5. 示例代码(LangChain4j + Ollama)
OllamaChatModel model = OllamaChatModel.builder()
.baseUrl("http://localhost:11434")
.modelName("deepseek-r1:14b")
.temperature(0.7) // 控制随机性
.topP(0.9) // 核采样
.maxTokens(500) // 限制生成长度
.frequencyPenalty(0.5) // 减少重复
.build();
String response = model.generate("请写一首关于春天的诗。");
System.out.println(response);总结
temperature:控制创造性(值越高,答案越多样)。top_p:控制候选词范围(避免低质量输出)。max_tokens:限制回答长度。frequency_penalty:减少重复内容。seed:固定随机性(可复现结果)。
调整这些参数可以优化模型输出,适应不同任务需求! 🚀
17.6.4 Prompt
Prompt 是指用户提供给 AI 系统的输入文本,用于引导或"提示"AI 生成相应的输出。它可以是问题、指令、不完整的句子或任何形式的文本输入。
Prompt 的作用
- 引导 AI 响应:决定 AI 生成内容的方向和风格
- 提供上下文:帮助 AI 理解用户的具体需求
- 控制输出:通过精心设计的 prompt 可以获得更精确的结果
Prompt 的类型
- 指令型:"写一封求职信"
- 问答型:"太阳系有多少颗行星?"
- 补全型:"从前有一个小村庄..."
- 示例型:提供输入输出的示例让 AI 模仿
好的 Prompt 特点
- 清晰明确:避免模糊表述
- 具体详细:包含必要细节
- 结构合理:逻辑清晰的组织
- 适当长度:既不太短也不冗余
Prompt 工程
专门优化 prompt 以获得更好 AI 输出的实践被称为"prompt 工程",包括:
- 尝试不同措辞
- 添加限制条件
- 提供示例
- 分步指示
在 AI 交互中,精心设计的 prompt 往往能显著提高获得理想结果的可能性。