一、晨考题
1、List 和 Set 的区别
- List:有序的、元素可重复的
- Set:无序的、元素不可重复的
2、栈和队列的区别
- 栈(叠罗汉、桶等):先进后出
- 队列:先进先出
3、Collection 和 Map 的区别
- Collection:存储一组对象,单列集合
- Map:存储一组键值对,双列集合
4、请写出 2 种哈希表的区别
- Hashtable:古老的,线程安全的,不支持 key 和 value 为 null,底层结构:数组+(单)链表
- HashMap:较新的,线程不安全的,支持 key 和 value 为 null,底层结构:数组 +(单)链表 + 红黑树(JDK7 及其之前也是数组+链表)
5、画集合关系图
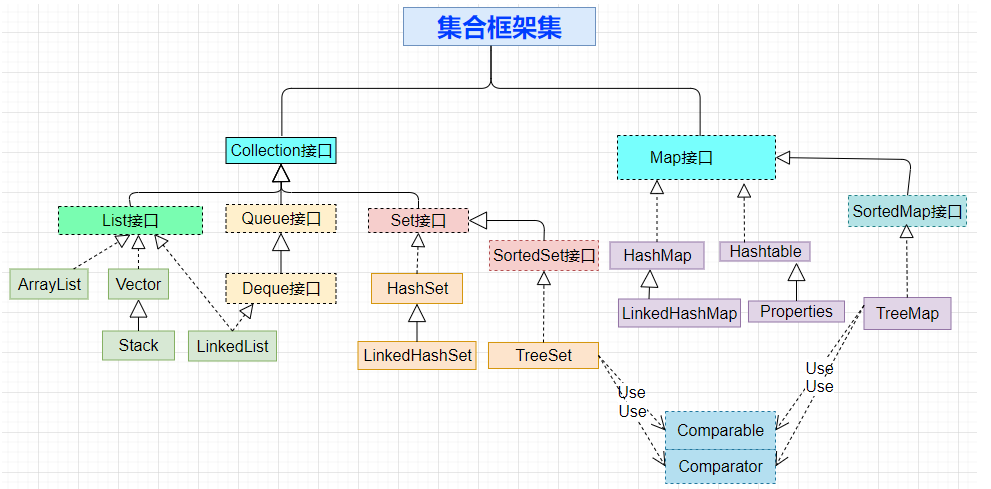
二、复习
1、两种动态数组的区别
- Vector:古老的,线程安全的,默认 2 倍扩容,初始容量 10,支持手动指定增量
- ArrayList:较新的,线程不安全,默认 1.5 倍扩容,初始容量 0,首次添加容量是 10,不支持手动指定增量
2、动态数组与 LinkedList/双向链表的区别
动态数组:
- 需要一整块连续的存储空间、通过下标访问元素效率很高
- 需要扩容,非末尾位置添加和删除需要移动元素
- 因为现在的内存拷贝技术比较高,所以动态数组的效率反而更高
双向链表
- 不要求元素是连续的
- 在 Java 中,链表的实现需要依赖于结点,创建结点、回收结点需要耗时耗力
- 不需要扩容,不需要移动元素
3、HashSet、LinkedHashSet、TreeSet 的区别
- HashSet:完全无规律,不按添加顺序,也不按大小顺序。底层是 HashMap。
- LinkedHashSet:按照添加顺序。底层是 LinkedHashMap。
- TreeSet:按照大小顺序。底层是 TreeMap。
4、HashMap、LinkedHashMap、TreeMap 的区别
- HashMap:完全无规律,不按(key,value)添加顺序,也不按 key 大小顺序。底层结构:数组 +(单)链表 + 红黑树(JDK7 及其之前也是数组+链表)
- LinkedHashMap:按照(key,value)添加顺序。底层结构:数组 +(单)链表 + 红黑树 + 双链表
- TreeMap:按照 key 的大小顺序。底层结构:红黑树
5、Iterable 和 Iterator 的区别
- Iterable:集合实现,重写 Iterator
iterate()方法,用于返回一个迭代器对象,表示集合可迭代的 - Iterator:在集合中用内部类实现它,重写 hasNext 和 next 方法,用于遍历集合的元素
6、Comparable 和 Comparator 的区别
- Comparable:自然比较接口,要比较大小的对象的类来实现它,重写 int
compareTo(T t) - Comparator:定制比较接口,需要独立的类(通常是匿名内部类)来实现它,重写 int
compare(T t1, T t2)
三、哈希表
3.1 树
请看《尚硅谷Java 基础第 11 章_集合原理分析(3)树.pptx》
3.2 哈希表

请看《尚硅谷Java 基础第 11 章_集合原理分析(4)哈希表.pptx》
package com.atguigu.map;
import java.util.Objects;
public class MyKey {//我们特殊设计的key,为了制造冲突而设计
private int num;
public MyKey(int num) {
this.num = num;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyKey myKey = (MyKey) o;
return num == myKey.num;
}
@Override
public int hashCode() {
if(num<=20){
return 1;//正常情况不要这么写,这里是为了演示冲突问题而改的
}
return Objects.hashCode(num);
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
@Override
public String toString() {
return "MyKey{" +
"num=" + num +
'}';
}
}package com.atguigu.map;
import org.junit.jupiter.api.Test;
import java.util.HashMap;
public class TestHashMap {
@Test
public void test(){
HashMap<Integer,String> map = new HashMap<>(50);
map.put(1,"hello");
System.out.println(map);
}
@Test
public void test2(){
HashMap<MyKey, Integer> map = new HashMap<>();
for(int i=1; i<=15; i++){
map.put(new MyKey(i), i);
}
/*
树化:
添加第9对时,扩容 16-32
添加第10对时,继续扩容 32-64
添加第11对时,树化
*/
}
@Test
public void test3(){
HashMap<MyKey, Integer> map = new HashMap<>();
for(int i=1; i<=11; i++){
map.put(new MyKey(i), i);
}
//上面的代码已经出现树化了
//演示反树化
for(int i=1; i<=5;i++){//删除5对
map.remove(new MyKey(i));
}
//通过上面的删除,树中还有6对
map.remove(new MyKey(6));
map.remove(new MyKey(7));//删除它变为链表
}
@Test
public void test4(){
HashMap<MyKey, Integer> map = new HashMap<>();
for(int i=1; i<=11; i++){
map.put(new MyKey(i), i);
}
//上面的代码已经出现树化了
for(int i=1; i<=5;i++){//删除5对
map.remove(new MyKey(i));
}
//通过上面的删除,树中还有6对
//演示反树化
//size=6
//这里i从21开始
for(int i=21; i<=100; i++){
map.put(new MyKey(i),i);
}
/*
现在的数组长度是64,loadfactor默认值是0.75, threshold=64*0.75=48
size>=48扩容
添加第49对时,[1]的树变为链表
*/
}
@Test
public void test5(){
HashMap<MyKey,String> map = new HashMap<>();
MyKey k1 = new MyKey(1);
MyKey k2 = new MyKey(2);
map.put(k1,"atguigu");//存的时候,hashCode用1
map.put(k2,"java");
System.out.println(map);
//错误操作
k1.setNum(100);//修饰k1对象的属性值
System.out.println(map);
String value = map.get(k1);
//get的时候,hashCode用100算的
System.out.println("value = " + value);
}
}package com.atguigu.map;
import java.util.Objects;
public class Student {
private String name;
private int score;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return score == student.score && age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, score, age);
}
}3.3 找素数
除了 31 之外,还有哪些数满足(1)素数(2)且是 2 的 n 次方-1
package com.atguigu.map;
import org.junit.jupiter.api.Test;
public class TestNumber {
@Test
public void test1(){
//找出1000以内素数且是2的n次-1的值
//循环2的n次值
for(int i=4; i<=1000; i*=2){
int num = i-1;//2的n次-1的值
//判断num是不是素数
/*
(1)普通范围[2, num-1]
如果在[2,num-1]范围内可以找到任一个整数可以把num整除,那么num不是素数。
在在[2,num-1]范围内找不到任意一个整数可以把num整除,那么num是素数。
(2)优化范围 [2, num的平方根
例如:以24为例 约数(排除1,24)
2,3,4,6,8,12
以36为例 约数(排除1,36)
2,3,4,6,9,12,18
*/
boolean flag = true;//假设num是素数
// for(int j=2; j<num; j++){
for(int j=2; j<=Math.sqrt(num); j++){
if(num%j==0){
flag = false;
break;
}
}
if(flag){
System.out.println(num+" ");
}
}
}
}四、Lambda 表达式和方法引用
Java8 引入很多好用的新特性:
- 接口的变化:接口中允许定义默认方法、静态方法
- 第 3 代日期时间 API
- Lambda 表达式和方法引用
- StreamAPI
4.1 什么是 Lambda 表达式
Lambda 表达式是一种语法糖(syntactic sugar),其目的是让代码更简洁、更易读,同时隐藏底层实现的复杂性。Lambda 表达式本质上是简化了函数式接口(只有一个抽象方法必须重写的接口)的实现方式。
Lambda 表达式用于简化匿名内部类实现函数式接口的代码。通常函数式接口是标记了@FunctionalInterface,Java 建议只针对标记了该注解的接口使用 Lambda 表达式。
回忆:只有一个抽象方法的接口有哪些?
Comparable
<T>:intcompareTo(T t)它没有@FunctionalInterfaceComparator
<T>:intcompare(T t1, T t2)Iterable
<T>:Iteratoriterator()它没有@FunctionalInterfaceConsumer
<T>:voidaccept(T t)Predicate
<T>:booleantest(T t).....
发现,没有标记@FunctionalInterface 的接口,虽然也只有一个抽象方法需要重写,但是不存在匿名内部类实现它们的场景。换句话说,标记了@FunctionalInterface 的函数式接口,通常都存在匿名内部类实现它们的场景。
Lambda 表达式的语法格式:
(形参列表) -> {Lambda体语句;}说明:
- (形参列表) :它就是 Lambda 表达式实现的函数式接口的抽象方法的(形参列表)
- {Lambda 体语句;}:它就是 Lambda 表达式实现的函数式接口的抽象方法的方法体
package com.atguigu.lambda;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class TestLambda {
@Test
public void test1(){
//对一组字符串排序,按照从短到长排序
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
System.out.println(list);
//[hello, java, world, atguigu, hi]
Comparator<String> c = new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
};//匿名内部类。这里强调要new一个对象,这个对象是实现了Comparator接口的类的对象。
//按照面向对象的编程思想:以对象为中心,特别在意new对象这个事
list.sort(c);
System.out.println(list);
//[hi, java, hello, world, atguigu]
}
@Test
public void test2(){
//对一组字符串排序,按照从短到长排序
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
System.out.println(list);
//[hello, java, world, atguigu, hi]
Comparator<String> c =(String o1, String o2) ->{return o1.length() - o2.length();};
//这是另一种编程思想的引入,它是函数式编程思想,这种思想关系的是如何实现这个功能,关系的是如何实现这个方法(函数),不关心“对象”
list.sort(c);
System.out.println(list);
//[hi, java, hello, world, atguigu]
}
}Lambda 表达式语法的简化:
- 当 Lambda 表达式的(形参列表)的类型可以根据泛型自动推断,或者类型是明确的,那么形参的类型完全可以省略
- 如果形参的类型省略了,形参只有 1 个话,()可以省略。其他情况()不能省略。
- 当 Lambda 表达式的{Lambda 体;},只有一个语句时,那么{} 和 这个语句的; 可以省略。如果这个语句同时还是一个 return 语句,那么 return 一起省略。
@Test
public void test3(){
//对一组字符串排序,按照从短到长排序
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
System.out.println(list);
//[hello, java, world, atguigu, hi]
/*
Comparator<T>接口的抽象方法:int compare(T t1, T t2)
形参的类型T,由Comparator<String>指定具体类型<String>,此时的T可以根据左边<>自动推断,那么它就可以省略
*/
// Comparator<String> c =(String o1, String o2) ->{return o1.length() - o2.length();};//未省略之前的
/* Comparator<String> c =(o1, o2) ->o1.length() - o2.length();//省略之后的
list.sort(c);*/
list.sort((s1, s2) ->s1.length() - s2.length());
System.out.println(list);
//[hi, java, hello, world, atguigu]
}4.2 常见的函数式接口
强调一下:Lambda 表达式是给函数式接口的变量或形参赋值用的,不能用在别的地方。
1、定制比较器 Comparator<T>
抽象方法:int compare(T t1 , T t2)
示例代码见上面
2、消费型接口 Consumer<T>
抽象方法:void accept(T t)
消费型:它的抽象方法是有参无返回值,类似于在方法体中把参数吃掉,消费掉了
| 序号 | 接口名 | 抽象方法 | 描述 |
|---|---|---|---|
| 1 | Consumer<T> | void accept(T t) | 接收一个对象用于完成功能 |
| 2 | BiConsumer<T,U> | void accept(T t, U u) | 接收两个对象用于完成功能 |
| 3 | DoubleConsumer | void accept(double value) | 接收一个 double 值 |
| 4 | IntConsumer | void accept(int value) | 接收一个 int 值 |
| 5 | LongConsumer | void accept(long value) | 接收一个 long 值 |
| 6 | ObjDoubleConsumer<T> | void accept(T t, double value) | 接收一个对象和一个 double 值 |
| 7 | ObjIntConsumer<T> | void accept(T t, int value) | 接收一个对象和一个 int 值 |
| 8 | ObjLongConsumer<T> | void accept(T t, long value) | 接收一个对象和一个 long 值 |
package com.atguigu.lambda;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.function.Consumer;
public class TestConsumer {
@Test
public void test1(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
//集合的遍历有一种方式是调用 forEach方法
Consumer<String> c = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
list.forEach(c);
}
@Test
public void test2(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
//集合的遍历有一种方式是调用 forEach方法
list.forEach( s -> System.out.println(s));//Lambda表达式
}
}3、判断型接口 Predicate<T>
抽象方法:boolean test(T t)
这类接口的抽象方法特点:有参,但是返回值类型是 boolean 结果。
| 序号 | 接口名 | 抽象方法 | 描述 |
|---|---|---|---|
| 1 | Predicate<T> | boolean test(T t) | 接收一个对象 |
| 2 | BiPredicate<T,U> | boolean test(T t, U u) | 接收两个对象 |
| 3 | DoublePredicate | boolean test(double value) | 接收一个 double 值 |
| 4 | IntPredicate | boolean test(int value) | 接收一个 int 值 |
| 5 | LongPredicate | boolean test(long value) | 接收一个 long 值 |
package com.atguigu.lambda;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.function.Predicate;
public class TestPredicate {
@Test
public void test1(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
//删除包a字母的单词
Predicate<String> p = new Predicate<String>() {
@Override
public boolean test(String s) {
return s.contains("a");
}
};
list.removeIf(p);
System.out.println(list);
}
@Test
public void test2(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
//删除包a字母的单词
list.removeIf(s-> s.contains("a"));
System.out.println(list);
}
}4、功能型接口 Function<T,R>
抽象方法:R apply(T t)
这类接口的抽象方法特点:既有参数又有返回值
| 序号 | 接口名 | 抽象方法 | 描述 |
|---|---|---|---|
| 1 | Function<T,R> | R apply(T t) | 接收一个 T 类型对象,返回一个 R 类型对象结果 |
| 2 | UnaryOperator<T> | T apply(T t) | 接收一个 T 类型对象,返回一个 T 类型对象结果 |
| 3 | DoubleFunction<R> | R apply(double value) | 接收一个 double 值,返回一个 R 类型对象 |
| 4 | IntFunction<R> | R apply(int value) | 接收一个 int 值,返回一个 R 类型对象 |
| 5 | LongFunction<R> | R apply(long value) | 接收一个 long 值,返回一个 R 类型对象 |
| 6 | ToDoubleFunction<T> | double applyAsDouble(T value) | 接收一个 T 类型对象,返回一个 double |
| 7 | ToIntFunction<T> | int applyAsInt(T value) | 接收一个 T 类型对象,返回一个 int |
| 8 | ToLongFunction<T> | long applyAsLong(T value) | 接收一个 T 类型对象,返回一个 long |
| 9 | DoubleToIntFunction | int applyAsInt(double value) | 接收一个 double 值,返回一个 int 结果 |
| 10 | DoubleToLongFunction | long applyAsLong(double value) | 接收一个 double 值,返回一个 long 结果 |
| 11 | IntToDoubleFunction | double applyAsDouble(int value) | 接收一个 int 值,返回一个 double 结果 |
| 12 | IntToLongFunction | long applyAsLong(int value) | 接收一个 int 值,返回一个 long 结果 |
| 13 | LongToDoubleFunction | double applyAsDouble(long value) | 接收一个 long 值,返回一个 double 结果 |
| 14 | LongToIntFunction | int applyAsInt(long value) | 接收一个 long 值,返回一个 int 结果 |
| 15 | DoubleUnaryOperator | double applyAsDouble(double operand) | 接收一个 double 值,返回一个 double |
| 16 | IntUnaryOperator | int applyAsInt(int operand) | 接收一个 int 值,返回一个 int 结果 |
| 17 | LongUnaryOperator | long applyAsLong(long operand) | 接收一个 long 值,返回一个 long 结果 |
| 18 | BiFunction<T,U,R> | R apply(T t, U u) | 接收一个 T 类型和一个 U 类型对象,返回一个 R 类型对象结果 |
| 19 | BinaryOperator<T> | T apply(T t, T u) | 接收两个 T 类型对象,返回一个 T 类型对象结果 |
| 20 | ToDoubleBiFunction<T,U> | double applyAsDouble(T t, U u) | 接收一个 T 类型和一个 U 类型对象,返回一个 double |
| 21 | ToIntBiFunction<T,U> | int applyAsInt(T t, U u) | 接收一个 T 类型和一个 U 类型对象,返回一个 int |
| 22 | ToLongBiFunction<T,U> | long applyAsLong(T t, U u) | 接收一个 T 类型和一个 U 类型对象,返回一个 long |
| 23 | DoubleBinaryOperator | double applyAsDouble(double left, double right) | 接收两个 double 值,返回一个 double 结果 |
| 24 | IntBinaryOperator | int applyAsInt(int left, int right) | 接收两个 int 值,返回一个 int 结果 |
| 25 | LongBinaryOperator | long applyAsLong(long left, long right) | 接收两个 long 值,返回一个 long 结果 |
总结:
- 当接口名以 Operator 结尾,不是以 Function 结尾时,说明形参的类型与方法返回值类型是一样,接收什么类型,返回什么类型。
- 当接口名中有 Unary,说明参数是 1 个,且形参的类型与方法返回值类型是一样
- 当接口名中 Bi 或 Binary,说明参数是 2 个
package com.atguigu.lambda;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.function.UnaryOperator;
public class TestFunction {
@Test
public void test1(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
//将上述单词全部转为大写
/*
UnaryOperator<T>接口是继承了Function<T,T>,抽象方法T apply(T t)
*/
UnaryOperator<String> u = new UnaryOperator<String>() {
@Override
public String apply(String s) {
return s.toUpperCase();
}
};
list.replaceAll(u);
System.out.println(list);
}
@Test
public void test2(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
//将上述单词全部转为大写
list.replaceAll(s -> s.toUpperCase());
System.out.println(list);
}
}5、供给型接口 Supplier<T>
抽象方法:T get()
抽象方法的特点是:无参有返回值。
| 序号 | 接口名 | 抽象方法 | 描述 |
|---|---|---|---|
| 1 | Supplier<T> | T get() | 返回一个对象 |
| 2 | BooleanSupplier | boolean getAsBoolean() | 返回一个 boolean 值 |
| 3 | DoubleSupplier | double getAsDouble() | 返回一个 double 值 |
| 4 | IntSupplier | int getAsInt() | 返回一个 int 值 |
| 5 | LongSupplier | long getAsLong() | 返回一个 long 值 |
示例代码见后面
4.3 自定义函数式接口
@FunctionalInterface
public interface 接口名{
必须有一个抽象方法
}package com.atguigu.lambda;
@FunctionalInterface
public interface Callable {
void call();
}package com.atguigu.lambda;
import org.junit.jupiter.api.Test;
public class TestCallable {
@Test
public void test1(){
Callable c = new Callable() {
@Override
public void call() {
System.out.println("柴老师喊你认真听课");
}
};
c.call();
}
@Test
public void test2(){
Callable c = () -> System.out.println("柴老师喊你认真听课");
c.call();
}
@Test
public void test3(){
Callable c = new Callable() {
@Override
public void call() {
System.out.println("柴老师喊你认真听课");
}
};
show(c);
}
@Test
public void test4(){
show(()->System.out.println("柴老师喊你认真听课"));
}
public void show(Callable c){
c.call();
}
}五、方法引用
方法引用的语法格式:
- 类名 :: 方法名
- 对象名 :: 方法名
- 类名 :: new
方法引用用于简化 Lambda 表达式。但是不是所有的 Lambda 表达式都可以用方法引用简化,必须满足一定条件才可以简化。一旦满足简化的条件,方法引用的写法肯定比 Lambda 表达式精简。
提醒:什么时候能用方法引用,或者 Lambda 表达式需要满足什么条件才能用方法引用,这个事你就算不知道,也没有关系,因为 IDEA 会给你提示。
(1)当Lambda表达式的方法体只有1个语句
(2)这个语句是调用一个现有的类或对象的方法来完成的
(3)Lambda体中这句语句需要的参数或调用方法的对象全部来源于Lambda表达式的形参列表,没有额外的数据参与
当Lambda体中唯一的语句是在new一个对象,new对象时给构造器的形参全部来源于 Lambda表达式的形参列表,就可以用 类名 :: newpackage com.atguigu.reference;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class TestReference {
@Test
public void test1(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
//集合的遍历有一种方式是调用 forEach方法
/*Consumer<String> c = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};//匿名内部类
list.forEach(c);
*/
//(1)Lambda表达式 简化了 匿名内部类写法
// list.forEach( s -> System.out.println(s));//Lambda表达式
//(2)用方法引用简化Lambda表达式
list.forEach(System.out::println);//方法引用
/*
(1)当Lambda表达式的方法体只有1个语句
(2)这个语句是调用一个现有的类或对象的方法来完成的
(3)Lambda体中这句语句需要的参数全部来源于Lambda表达式的形参列表,没有额外的数据参与
*/
list.forEach( s -> System.out.println("尚硅谷:" + s));
//不能用方法引用简化,因为"尚硅谷:" 是Lambda表达式形参列表之外的东西
}
@Test
public void test2(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","world","atguigu","hi");
//将上述单词全部转为大写
/* UnaryOperator<String> u = new UnaryOperator<String>() {
@Override
public String apply(String s) {
return s.toUpperCase();
}
};//匿名内部类
list.replaceAll(u);*/
// list.replaceAll(s -> s.toUpperCase());//Lambda表达式
list.replaceAll(String::toUpperCase);//Lambda表达式
System.out.println(list);
}
@Test
public void test3(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","Java","world","atguigu","Hi");
/* Comparator<String> c = new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareToIgnoreCase(o2);
}
};//匿名内部类
list.sort(c);*/
// list.sort((o1,o2)->o1.compareToIgnoreCase(o2));//Lambda表达式
list.sort(String::compareToIgnoreCase);//Lambda表达式
System.out.println(list);
}
@Test
public void test4(){
ArrayList<Employee> list = new ArrayList<>();
list.add(new Employee("小刚",12000));
list.add(new Employee("小轩",14000));
list.add(new Employee("小鹏",11000));
list.add(new Employee("小韩",16000));
/*
Comparator<Employee> c = new Comparator<Employee>() {
@Override
public int compare(Employee o1, Employee o2) {
return Double.compare(o1.getSalary(),o2.getSalary());
}
};//匿名内部类
list.sort(c);*/
// list.sort((o1,o2) -> Double.compare(o1.getSalary(),o2.getSalary()));//Lambda表达式
/*
ToDoubleFunction<T>接口double applyAsDouble(T value)
*/
/* ToDoubleFunction<Employee> t = new ToDoubleFunction<Employee>() {
@Override
public double applyAsDouble(Employee e) {
return e.getSalary();
}
};//匿名内部类
list.sort(Comparator.comparingDouble(t));*/
// list.sort(Comparator.comparingDouble(e->e.getSalary()));//Lambda表达式
list.sort(Comparator.comparingDouble(Employee::getSalary));//方法引用
System.out.println(list);
}
}六、StreamAPI
当时将 IO 流章节提到过 InputStream、OutputStream 等,有 Stream 这个单词,Stream 在这里是代表读、写过程中数据流动的概念。
6.1 什么是 StreamAPI
这里的 Stream 是指对数据加工处理过程中数据流动概念。所谓的加工处理是什么意思?是指对数据进行筛选、统计分析、过滤、去重等操作。Java 希望设计一套 API 对内存中的数据(内存中的数据通常是存储在数组、集合中 数据)进行管理,像 SQL 对数据库中的数据一样管理。
StreamAPI 的使用分为 3 个步骤:
- 创建 Stream,即指定数据源
- 加工处理:0 ~ n 步
- 终结操作:最后一步。
- 如果这个方法的返回值类型不再是 Stream,那么就属于终结操作。
- 如果这个方法的返回值类型仍然是 Stream,那么就属于中间操作。
StreamAPI 的操作有一些特点:
- 不会改变数据源
- 每一次操作都会返回新的 Stream
- Stream 大部分操作都是惰性求值,即直到遇到终结操作,才会一起执行中间操作,否则可能中间操作不执行。
package com.atguigu.stream;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;
//@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private String name;
private int score;
public int getScore() {
System.out.println("获取分数");
return score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", score=" + score +
'}';
}
}package com.atguigu.stream;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class TestStream {
@Test
public void test1(){
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("张三",89));
list.add(new Student("李四",60));
list.add(new Student("王五",52));
list.add(new Student("赵六",55));
//找出成绩不及格的同学
//创建Stream
Stream<Student> stream = list.stream();
//中间加工处理
/*Predicate<Student> p = new Predicate<Student>() {
@Override
public boolean test(Student student) {
return student.getScore() < 60;
}
};
stream.filter(p);*/
stream = stream.filter(student -> student.getScore() < 60);
//终结操作
List<Student> result = stream.toList();
// System.out.println(result);
System.out.println(list);
}
}6.2 创建 Stream
1、Arrays 工具类的方法可以创建 Stream
2、Collection 系列集合.stream 方法(最多)
3、Stream.of(元素列表)
4、Stream.generate 或 iterate 产生无限流
package com.atguigu.stream;
import org.junit.jupiter.api.Test;
import java.util.*;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class TestCreateStream {
@Test
public void test1(){
int[] arr = {10,20,30,40,50};
IntStream stream = Arrays.stream(arr);
System.out.println(stream);
//java.util.stream.IntPipeline$Head@5762806e
}
@Test
public void test2(){
int[] arr = {10,15,30,45,50};
//统计里面偶数的个数
IntStream stream = Arrays.stream(arr);
//Predicate<T> boolean test(T t)
stream = stream.filter(t->t%2==0);
long count = stream.count();
System.out.println("count = " + count);
}
@Test
public void test3(){
int[] arr = {10,15,30,45,50};
System.out.println(Arrays.stream(arr).filter(t -> t % 2 == 0).count());
}
@Test
public void test4(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","atguigu");
Stream<String> stream = list.stream();
///....
}
@Test
public void test5(){
//找出一组单词中包含a字母的单词
//Predicate<T> boolean test(T t)
List<String> list = Stream.of("hello", "java", "atguigu").filter(t -> t.contains("a")).toList();
System.out.println(list);//[java, atguigu]
}
@Test
public void test6(){
//产生一组[0,100)之间的整数
Random r = new Random();
/* Supplier<Integer> s = new Supplier<Integer>() {
@Override
public Integer get() {
return r.nextInt(100);
}
};
Stream.generate(s);*/
/* Consumer<Integer> c = new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
};*/
// Stream.generate(s).forEach(c);
Stream.generate(() -> r.nextInt(100)) //创建Stream
.limit(10) //限制10个 中间处理
.forEach(integer -> System.out.println(integer)); //终结操作
}
@Test
public void test7(){
//不断的迭代iterate,即从种子1开始,不断的加2
/*UnaryOperator<Integer> u = new UnaryOperator<Integer>() {
@Override
public Integer apply(Integer integer) {
return integer + 2;
}
};*/
// Stream.iterate(1, u).forEach(integer -> System.out.println(integer));
Stream.iterate(1, integer -> integer+2).forEach(integer -> System.out.println(integer));
}
}6.2 中间的加工处理
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
| 序号 | 方 法 | 描 述 |
|---|---|---|
| 1 | Stream filter(Predicate p) | 接收 Lambda , 从流中排除某些元素 |
| 2 | Stream distinct() | 筛选,通过流所生成元素的equals() 去除重复元素 |
| 3 | Stream limit(long maxSize) | 截断流,使其元素不超过给定数量 |
| 4 | Stream skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补 |
| 5 | Stream peek(Consumer action) | 接收 Lambda,对流中的每个数据执行 Lambda 体操作 |
| 6 | Stream sorted() | 产生一个新流,其中按自然顺序排序 |
| 7 | Stream sorted(Comparator com) | 产生一个新流,其中按比较器顺序排序 |
| 8 | Stream map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| 9 | Stream mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。 |
| 10 | Stream mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。 |
| 11 | Stream mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。 |
| 12 | Stream flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
package com.atguigu.stream;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
public class TestMiddle {
@Test
public void test1(){
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 5,6,8,9,4,2,9,3,9);
//筛选出所有的奇数,且不重复
//统计奇数的个数,并且查看是哪些奇数
long result = list.stream() //创建Stream
.filter(t -> t % 2 != 0) //Predicate<T> boolean test(T t) 过滤筛选
.distinct() //去重
.peek(t -> System.out.println(t)) //Consumer<T> void accept(T t) 查看元素
.count(); //终结操作,统计个数
System.out.println("个数:" + result);
}
@Test
public void test2(){
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 5,6,8,9,4,2,9,3,9,8,6);
//找出第2,第3大的数字 结果是8,6
list.stream() //创建Stream
.distinct()
.sorted((t1,t2) -> t2-t1) //Comparator<T> int compare(T t1, T t2)
.skip(1)
.limit(2)
.forEach(t -> System.out.println(t));//Consumer<T> void accept(T t) 查看元素
}
@Test
public void test3(){
/*
map和flatMap操作:映射。意思是把某个操作 作用到每一个元素上,通常会修改元素的值。
map:可以修改元素的值,类型,但不能修改元素的个数
flatMap:可能改变的元素的值,类型,个数。
因为flatMap会把每一个元素 单独处理,处理后得到一个小的Stream。最后把这些Stream再合并成一个大的Stream。
例如: 5,6,8
map操作的结果可能是 3,2,4
"五","二","四"
flatMap的操作结果可能是 5->1,2,2 6->1,2,3 8->2,2,4,合并为 1,2,2,1,2,3,2,2,4
*/
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","atguigu");
//将上述单词的首字母提取出来
list.stream()
.map(s-> s.charAt(0)) //Function<T,R> 抽象方法:R apply(T t)
.forEach(System.out::println);
}
@Test
public void test4(){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "hello","java","atguigu");
//把上面的单词,每一个字母拆出来
list.stream()
.flatMap(s-> Arrays.stream(s.split("|"))) //Function<T,R> 抽象方法:R apply(T t) 这里 R一定是一个Stream
.forEach(System.out::println);
}
}6.3 终结操作
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void。流进行了终止操作后,不能再次使用。
| 序号 | 方法的返回值类型 | 方法 | 描述 |
|---|---|---|---|
| 1 | boolean | allMatch(Predicate p) | 检查是否匹配所有元素 |
| 2 | boolean | anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| 3 | boolean | noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| 4 | Optional<T> | findFirst() | 返回第一个元素 |
| 5 | Optional<T> | findAny() | 返回当前流中的任意元素 |
| 6 | long | count() | 返回流中元素总数 |
| 7 | Optional<T> | max(Comparator c) | 返回流中最大值 |
| 8 | Optional<T> | min(Comparator c) | 返回流中最小值 |
| 9 | void | forEach(Consumer c) | 迭代 |
| 10 | T | reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 T |
| 11 | U | reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 Optional<T> |
| 12 | R | collect(Collector c) | 将流转换为其他形式。接收一个 Collector 接口的实现,用于给 Stream 中元素做汇总的方法 |
Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。另外, Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例。
package com.atguigu.stream;
import org.junit.jupiter.api.Test;
import java.util.*;
import java.util.stream.Collectors;
public class TestEnding {
@Test
public void test1(){
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1,2,3,4,5);
//求它们的累加和
Optional<Integer> result = list.stream()
.reduce((a, b) -> a + b);//BinaryOperator<T> T apply(T t, T u)
System.out.println(result);//Optional[15]
Integer sum = result.orElse(0);//如果Optional非空,返回实际的值,如果为空,返回备用值
System.out.println(sum);
}
@Test
public void test2(){
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 11,21,31,41,51);
//求上述整数中所有偶数的累加和
Optional<Integer> result = list.stream()
.filter(t->t%2==0) //Predicate<T> boolean test(T t)
.reduce((a, b) -> a + b);//BinaryOperator<T> T apply(T t, T u)
System.out.println(result);
//Optional是一个小型容器,用于包装一个对象,通常是一个结果对象。用于避免空指针异常。
//如果有时候计算完是没有结果的,结果是null,如果直接返回null,容易引起空指针异常,所以返回Optional
Integer sum = result.orElse(0);
System.out.println(sum);
}
@Test
public void test3(){
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1,2,3,4,5);
//将上述数字中的偶数收集出来,放到一个单独的List中
List<Integer> evenList = list.stream()
.filter(t -> t % 2 == 0)
.toList();//toList()JDK16之后才有的
System.out.println(evenList);
}
@Test
public void test4(){
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1,2,3,4,5);
//将上述数字中的偶数收集出来,放到一个单独的List中
List<Integer> evenList = list.stream()
.filter(t -> t % 2 == 0)
.collect(Collectors.toList());
System.out.println(evenList);
}
@Test
public void test5(){
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1,2,3,2,6,8,2,4,4,5);
//将上述数字中的偶数收集出来,放到一个单独的Set中
Set<Integer> set = list.stream()
.filter(t -> t % 2 == 0)
.collect(Collectors.toSet());
System.out.println(set);//[2, 4, 6, 8]
}
@Test
public void test6(){
ArrayList<Employee> list = new ArrayList<>();
list.add(new Employee("张三",'男',18000));
list.add(new Employee("李四",'女',15000));
list.add(new Employee("王五",'男',12000));
list.add(new Employee("赵六",'女',13000));
list.add(new Employee("钱七",'男',11000));
//将上述员工对象的姓名和薪资提取出来,姓名为key,薪资为value
/*
toMap方法的形参有2个:
toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper)
第1个形参是 Function<? super T, ? extends K> keyMapper, 抽象方法 R apply(T t) 从上述的员工对象中提取name作为key
第2个形参Function<? super T, ? extends U> valueMapper , 抽象方法 R apply(T t) 从上述的员工对象中提取salary作为value
*/
Map<String, Double> map = list.stream()
.collect(Collectors.toMap(e -> e.getName(), e -> e.getSalary()));
System.out.println(map);
}
@Test
public void test7(){
ArrayList<Employee> list = new ArrayList<>();
list.add(new Employee("张三",'男',18000));
list.add(new Employee("李四",'女',15000));
list.add(new Employee("王五",'男',12000));
list.add(new Employee("赵六",'女',13000));
list.add(new Employee("钱七",'男',11000));
//求上述员工对象的薪资的最高值(max)、最低值(min)、平均值(avg)、总和(sum)、人数(count)
DoubleSummaryStatistics result = list.stream()
.collect(Collectors.summarizingDouble(t -> t.getSalary()));//toDoubleFunction<T> Double apply(T t)
System.out.println(result);
//DoubleSummaryStatistics{count=5, sum=69000.000000, min=11000.000000, average=13800.000000, max=18000.000000}
}
@Test
public void test8(){
ArrayList<Employee> list = new ArrayList<>();
list.add(new Employee("张三",'男',18000));
list.add(new Employee("李四",'女',15000));
list.add(new Employee("王五",'男',12000));
list.add(new Employee("赵六",'女',13000));
list.add(new Employee("钱七",'男',11000));
//按照男和女分为2组
/*
groupingBy(Function<? super T, ? extends K> classifier)
Function接口的抽象方法 R apply(T t)
*/
Map<Character, List<Employee>> map = list.stream()
.collect(Collectors.groupingBy(e -> e.getGender()));
//遍历map
Set<Map.Entry<Character, List<Employee>>> entries = map.entrySet();
for (Map.Entry<Character, List<Employee>> entry : entries) {
Character gender = entry.getKey();
System.out.println(gender );
List<Employee> all = entry.getValue();
for (Employee e : all) {
System.out.println("\t" + e);
}
}
}
@Test
public void test9(){
ArrayList<Employee> list = new ArrayList<>();
list.add(new Employee("张三",'男',18000));
list.add(new Employee("李四",'女',15000));
list.add(new Employee("王五",'男',12000));
list.add(new Employee("赵六",'女',13000));
list.add(new Employee("钱七",'男',11000));
//按照男和女分组,统计人数
/*
groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream)
第1个形参是 取key作为分组依据
第2个形参是 仍然是Collector,对按照第1个参数分组后的结果再次收集统计
*/
Map<Character, Long> result = list.stream()
.collect(Collectors.groupingBy(e -> e.getGender(), Collectors.counting()));
System.out.println(result);
}
@Test
public void test10(){
ArrayList<Employee> list = new ArrayList<>();
list.add(new Employee("张三",'男',18000));
list.add(new Employee("李四",'女',15000));
list.add(new Employee("王五",'男',12000));
list.add(new Employee("赵六",'女',13000));
list.add(new Employee("钱七",'男',11000));
//按照男和女分组,找出薪资最高的
Map<Character, Optional<Employee>> map = list.stream()
.collect(Collectors.groupingBy(e -> e.getGender(), Collectors.maxBy((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()))));
System.out.println(map);
}
}