复习
1.1 2 种实现多线程的方式
继承 Thread 类
实现 Runnable 接口
- 当不能继承 Thread 类时,因为类与类之间有单继承的限制,那么改为实现 Runnable 接口来解决
- 它们都必须重写 public void
run()方法 - 它们的启动都需要用 Thread 类的
start()方法
1.2 Thread 类的部分方法
Thread.sleep(时间):休眠 xx 时间线程 a.
join():执行这句代码的线程是 main 线程,线程 a 阻塞 main 线程,即 main 线程必须等 a 线程结束才能继续。如果此时还有 1 个 b 线程已经启动的情况下,a 和 b 仍然同时执行。线程
a.join(时间):执行这句代码的线程是 main 线程,线程 a 阻塞 main 线程,即 main 线程必须等 a 线程一段时间之后才能继续。线程
a.stop():让线程 a 停止,但是这个方法已过时,不推荐使用。建议通过设置变量等,来控制线程的执行。线程
a.setName(线程名)或 线程a.getName():默认的线程名称是 Thread-编号,main 线程的名称默认是 main。当然线程可以设置独特的名字。Thread.currentThread():获取执行这句代码的当前线程。1.3 线程安全问题
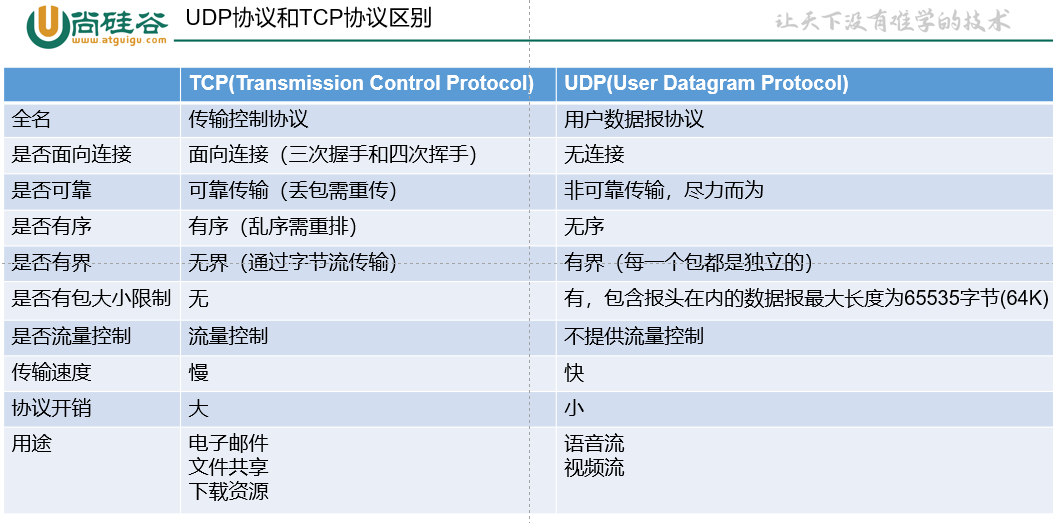
(1)3 代的日期时间 API:第 1 和 2 代都线程不安全。第 3 代是线程安全的。
(2)String、StringBuffer、StringBuilder 三种字符串:String 是不可变,线程安全的。StringBuffer 是可变字符串,线程安全。StringBuilder 是新的可变字符串,线程不安全的。
(3)List 集合中:Vector 和 Stack 是线程安全的,ArrayList、LinkedList 是线程不安全的。
(4)Set 集合:HashSet、LinkedHashSet、TreeSet 都不安全
(5)Map 集合:Hashtable、Properties 是线程安全的,HashMap、LinkedHashMap、TreeMap 是线程不安全的
如果使用某个集合线程不安全,怎么办?
- 自己使用 synchronized 等锁解决
- 调用 Collections 工具类的 synchronizedXxx 方法来解决
如何使用 synchronized?
同步代码块:
synchronized(所长对象){
需要加锁的代码,单次不可拆分的原子性的任务
}同步方法:
【其他修饰符】 synchronized 返回值类型 方法名(【形参列表】)【throws 异常列表】{
}
//静态方法:所长对象是 当前类的Class对象
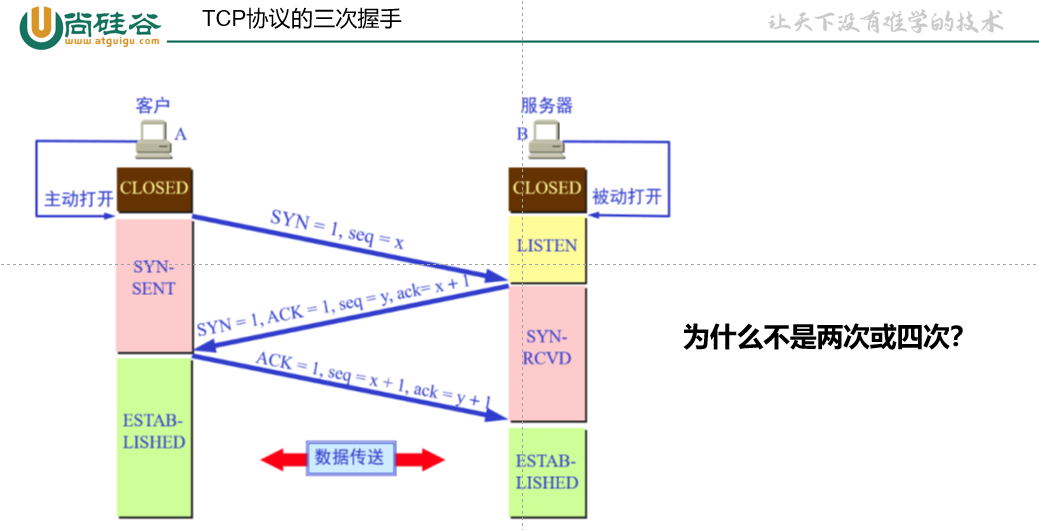
//非静态方法:所长对象是 this一旦使用 synchronized,就要明确两个问题:
锁的代码范围是否合适
锁对象是否是“同一个”
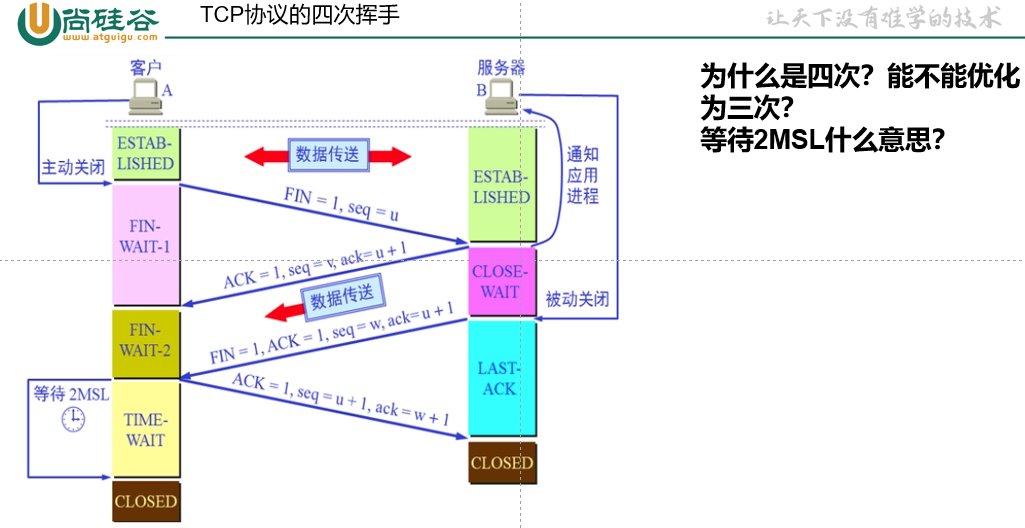
1.4 单例设计模式
(1)饿汉式
public class 类名{
public static final 类名 对象名 = new 类名();
private 类名(){
}
//其他成员正常定义
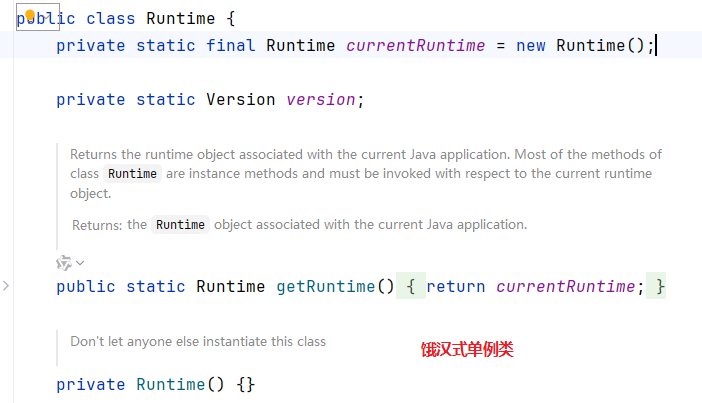
}(2)饿汉式
public class 类名{
private static final 类名 对象名 = new 类名();
private 类名(){
}
public static 类名 方法名(){
return 对象名;
}
//其他成员正常定义
}
(3)饿汉式
public enum 类名{
对象名;
//其他成员正常定义
}(4)懒汉式
public class 类名{
private static 类名 对象名;
private 类名(){
}
public static 类名 方法名(){
if(对象名 == null){
synchronized(类名.class){
if(对象名 == null){
对象名 = new 类名();
}
}
}
return 对象名;
}
//其他成员正常定义
}public class 类名{
private static 类名 对象名;
private 类名(){
}
public static synchronized 类名 方法名(){
if(对象名 == null){
对象名 = new 类名();
}
return 对象名;
}
//其他成员正常定义
}(5)懒汉式
public class 类名{
private 类名(){
}
private class 内部类{
static 类名 对象名 = new 类名();
}
public static 类名 方法名(){
return 内部类.对象名;
}
//其他成员正常定义
}一、AI 大模型
1.1 了解 AI 大模型
1.1.1 国际主流 AI 大模型
- OpenAI GPT-4o(GPT-5 系列)
- 特点:参数规模突破 10 万亿,支持多模态输入(文本、图像、音频、视频),推理能力接近人类水平,在复杂逻辑和跨领域知识整合中表现突出。
- 应用场景:科研分析、跨行业决策支持、全媒体内容生成。
- 优势:技术领先,生态完善;劣势:商业化程度高,部分功能收费。
- Google Gemini 2.0 Ultra
- 特点:原生多模态架构,支持 100+语言实时互译,深度集成 Google 生态(搜索、办公套件),上下文窗口扩展至 200 万 token。
- 应用场景:全球化企业协作、实时翻译、多模态搜索引擎优化。
- Anthropic Claude 3.5-Sonnet(Anthropic)
- 特点:200K~1M tokens 上下文窗口,宪法 AI 架构确保合规性,医疗和法律领域表现卓越。
- 应用场景:法律文书分析、医疗诊断辅助、高安全性对话系统。
- Meta LLaMA-3(Facebook)
- 特点:开源 700 亿参数模型,推理速度提升 200%,在开源社区中性能接近 GPT-4。
- 应用场景:中小企业定制化 AI 解决方案、学术研究。
- Falcon-200B(阿联酋 TII)
- 特点:1800 亿参数开源模型,数学推理和代码生成能力对标 GPT-4,训练成本仅为同类模型的 1/3。
1.1.2 国内主流 AI 大模型
- DeepSeek-V3(深度求索)
- 特点:文科能力(78.2 分)超越多数国际竞品,理科(72.0 分)均衡,API 服务模式适合开发者集成。
- 优势:低成本训练(仅 600 万美元),推理效率高。
- 通义千问(Qwen2.5-Max,阿里巴巴)
- 特点:中文理解全球领先,数学和编程能力单项第一,支持百万级上下文窗口和多模态交互。
- 优势:全尺寸开源(7B~110B 参数),Hugging Face 开源生态排名第一。
- 文心一言 4.0(百度)
- 特点:深度整合百度知识图谱,在医疗、教育、金融等领域应用广泛,日均调用量 15 亿次。
- 豆包 1.5-Pro(字节跳动)
- 特点:稀疏 MoE 架构,训练成本低但性能等效 7 倍 Dense 模型,擅长语音识别和实时交互。
- 讯飞星火(科大讯飞)
- 特点:语音识别与合成能力行业标杆,支持 30+语言交互,教育场景应用广泛。
- 腾讯混元 TurboS
- 特点:万亿参数规模,支持文本到视频生成,在 Chatbot Arena 排名全球前八。
- 智谱清言 GLM-4(清华大学)
- 特点:国内首个支持视频通话的千亿参数模型,知识问答和创意写作能力均衡。
1.1.3 AI 大模型发展趋势
- 多模态融合(如 GPT-4o、Gemini 2.0 支持文本+图像+视频)。
- 低成本训练与推理优化(如 DeepSeek 的强化学习降低算力依赖)。
- 开源生态崛起(如通义千问、LLaMA-3 推动中小企业和垂直领域应用)。
- 行业专用模型(如百川大模型专精医疗,商汤 SenseChat 优化自然语言生成)。
目前 AI 大模型呈现“中美双强”格局:
- 国际巨头(OpenAI、Google)在技术和生态上领先,但面临监管和数据隐私挑战。
- 中国模型(如 DeepSeek、通义千问)在中文场景和行业应用中表现突出,并通过开源和低成本训练快速追赶。
未来,模型能力的提升将更多依赖算法优化而非单纯参数扩张,同时开源生态和端侧应用或成竞争关键点
1.1.4 AI 大模型编程能力排名
2025 年 7 月全球 AI 大模型编程能力排名中,Claude 3.7 Sonnet 以 91.2 分位列榜首,DeepSeek R1 和通义千问 Qwen2.5-Max 分别代表国际与国内顶尖水平。
全球编程能力排名及关键指标
- Claude 3.7 Sonnet(Anthropic)
- HumanEval 评测得分 91.2 分,支持 10 万 token 长文档解析,代码生成能力断层领先。
- DeepSeek R1(深度求索)
- 国产开源模型代表,中文长文本处理专家,ReLE 评测编程得分 87.7%,推理速度提升 3 倍。
- 通义千问 Qwen2.5-Max(阿里云)
- Chatbot Arena 全球编程单项第一,多模态融合任务支持全栈开发(通义灵码)。
- GPT-4.5(OpenAI)
- 综合理科能力得分 87.3 分,支持 32K 上下文,代码生成能力保持国际第一梯队。
- Gemini 2.0(Google)
- 原生多模态架构标杆,百万级上下文窗口适配工业级代码开发。
细分领域优势对比
- 开源模型性价比:DeepSeek R1 训练成本仅为 OpenAI 同类模型的 1/27,开发者可直接调用 API 或部署私有化版本。
- 多模态编程支持:通义千问 Qwen2.5-Omni-7B 支持文本、图像、音频、视频全模态交互,适合复杂任务处理。
- 企业级应用:百度文心一言 4.0 中文场景优化领先,已服务 8 万企业用户,适配标准化开发需求。
选型建议
- 科研与开发:优先选择 DeepSeek R1(开源生态)或 Claude 3.7 Sonnet(顶尖性能)。
- 多模态集成:通义千问 Qwen2.5-Max 提供全栈工具链,支持 AI 全生命周期开发。
- 成本敏感场景:开源模型(如 DeepSeek-V3、Qwen2.5-Omni-7B)日均调用成本低于商用模型 30%。
1.2 申请 API-Key
1.2.1 为什么需要 API-Key
调用大模型需要 API Key 主要是出于以下几个原因:
1. 身份验证(Authentication)
- API Key 相当于你的“数字身份证”,用于验证请求的合法性,确保只有授权的用户或应用程序可以访问服务。
- 防止未授权的滥用或恶意攻击,比如 DDoS 攻击、数据爬取等。
2. 访问控制(Access Control)
- 不同的用户可能有不同的权限(如免费试用、付费订阅、企业级访问等),API Key 可以帮助服务商区分用户级别。
- 例如,OpenAI 的 API Key 可以关联到具体的账户,限制调用次数或计算资源。
3. 计费和配额管理(Billing & Rate Limiting)
- 大模型的运行成本很高(如 GPT-4 单次推理可能消耗大量算力),API Key 可以关联到计费账户,按调用次数或 Token 数量收费。
- 同时,服务商可以通过 API Key 限制用户的请求频率(Rate Limit),防止资源被单个用户耗尽。
4. 安全性和审计(Security & Auditing)
- 如果某个 API Key 被滥用(如发送违规内容),服务商可以快速封禁该 Key,而不会影响其他用户。
- 所有通过 API Key 的请求会被记录,便于追踪问题或分析使用情况。
5. 防止模型滥用(Preventing Misuse)
- 大模型可能被用于生成有害内容、垃圾信息或自动化攻击,API Key 可以帮助平台监控和限制违规行为。
类比理解:想象 API Key 就像酒店的房卡:
- 没有房卡 → 无法进入房间(无法调用 API)。
- 不同的房卡 → 可能对应不同的权限(如普通客房 vs 行政套房)。
- 丢失房卡 → 可以注销旧卡,换新卡(防止泄露后滥用)。
注意事项
- 保护好 API Key,不要泄露(比如上传到 GitHub),否则可能被他人盗用,导致高额账单或封号。
- 部分大模型也提供免费试用的 Key(如 OpenAI 的免费额度),但通常有调用限制。
1.2.2 如何申请 API-Key
以通义千问为例:
第一步:访问网址:大模型服务平台百炼控制台 (aliyun.com)
第二步:注册并登录
第三步:实名认证
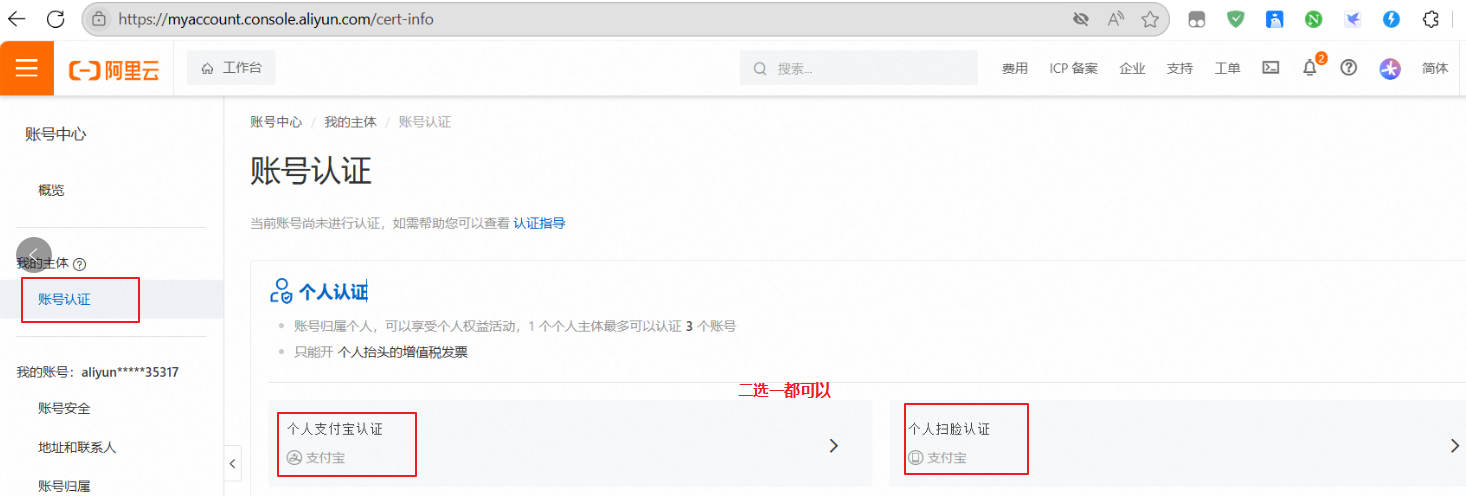
第四步:开通服务并创建 API-Key
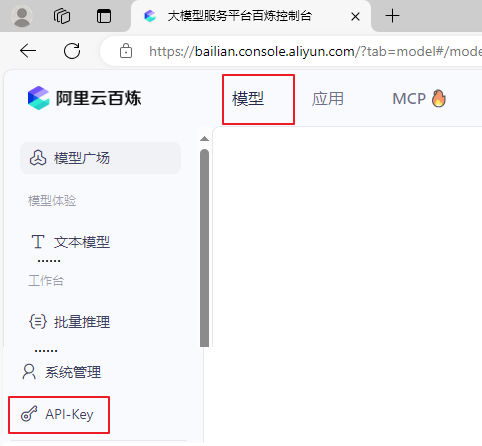


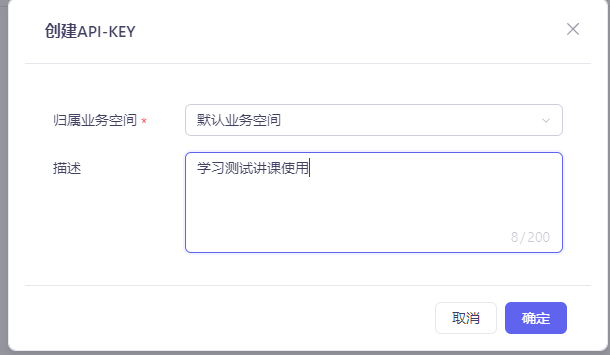

1.2.3 Token
1、什么是 Token?
在自然语言处理(NLP)和大语言模型(如 GPT、Claude)中,Token 是文本处理的基本单位,可以理解为模型“读取”和“生成”文字时的最小片段。它可以是一个单词、一个子词(subword),甚至是一个字符,具体取决于模型的分词方式(Tokenization)。Token 的常见形式:
(1) 英文 Token
- 完整单词:例如
"hello"、"world"各算 1 个 token。 - 子词(Subword):
"unhappiness"→"un" + "happiness"(2 tokens)"ChatGPT"→"Chat" + "G" + "PT"(3 tokens)- 常用词可能完整保留,罕见词会被拆分。
(2) 中文 Token
- 单字:如
"你好"→"你" + "好"(2 tokens)。 - 词组:部分模型会合并常见词组,如
"人工智能"可能算 1 token(取决于分词器)。 - 标点符号:
,。!?等通常各算 1 token。
(3) 代码 Token
- 变量名、关键字、符号都可能被拆分,例如:
print("Hello")→["print", "(", "\"", "Hello", "\"", ")"](6 tokens)。
2、为什么 Token 重要?
(1) 影响模型的计算和成本
- 上下文窗口限制:模型能处理的 Token 数量有限(如 GPT-4 支持 128K tokens)。
- API 计费:许多 AI 服务(如 OpenAI、Anthropic)按 Token 数量收费(输入+输出)。
(2) 影响模型的理解能力
- Token 划分方式 影响模型对语义的理解。
- 例如,
"ChatGPT"被拆成"Chat" + "G" + "PT",可能影响模型对缩写词的识别。
- 例如,
3、 如何计算 Token 数量?
(1) 使用官方工具
OpenAI Tokenizer(https://platform.openai.com/tokenizer)
- 输入文本即可查看如何被拆分。
- 例:
"你好,世界!"→ 5 tokens(你、好、,、世界、!)。
火山方舟(https://console.volcengine.com/ark/region:ark+cn-beijing/tokenCalculator)
(2) 估算方法
- 英文:1 token ≈ 4 字符(或 0.75 单词)。
- 中文:1 token ≈ 1~2 个汉字(取决于分词器)。
- 代码:1 token ≈ 2~5 字符(变量名、符号较多)。
二、网络编程
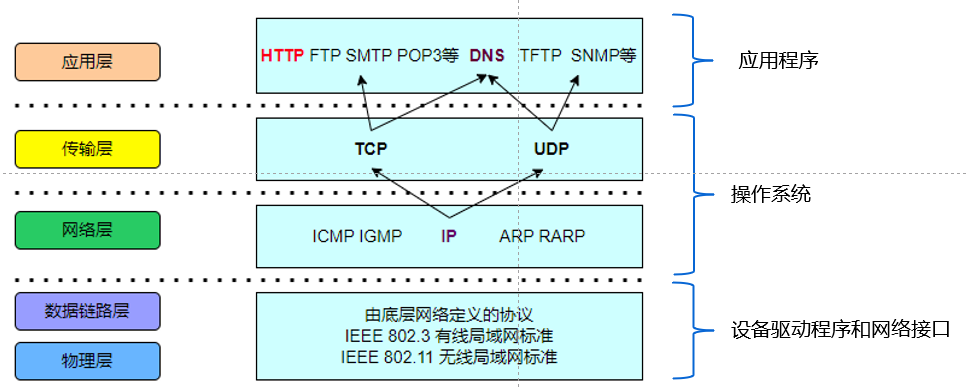
2.1 网络应用程序开发的三要素(了解)
1、IP 地址和域名


2、端口号

3、网络协议

2.2 Socket 分类(了解)
Java 中要进行网络应用程序开发,需要用到 Socket 类。Socket 被称为套接字。
Socket 的对象是负责与网卡驱动进行交互的对象。Socket 可以分为 2 类:
- 流套接字:ServletSocket 和 Socket,为 TCP 协议程序服务的
- 数据报套接字:DatagramSocket,为 UDP 协议程序服务的
2.3 基于 UDP 协议编程
- 发送端
package com.atguigu.net.udp;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Inet4Address;
import java.net.InetAddress;
public class Send {
public static void main(String[] args) throws Exception{
DatagramSocket ds = new DatagramSocket();//告诉网卡驱动,我要准备与网络进行通信
//操作系统会给我们Send程序随机分配一个端口号,指定本机IP
//对数据打包
String str = "这周四上午笔试,下午面试";
byte[] data = str.getBytes("UTF-8");
byte[] address = {(byte)192,(byte)168,39,60};//给谁发,写谁的IP地址
/*
192:
4个字节 00000000 00000000 00000000 11000000
截断为一个字节 11000000
如果是不考虑符号位
*/
InetAddress ip = Inet4Address.getByAddress(address);//接收方的IP
DatagramPacket dp = new DatagramPacket(data,0,data.length,ip,8888);//接收方的端口号
//发送数据报包
ds.send(dp);
System.out.println("发送完毕");
ds.close();//释放资源
}
}- 接收端
package com.atguigu.net.udp;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
public class Receive {
public static void main(String[] args) throws Exception{
DatagramSocket ds = new DatagramSocket(8888);//告诉网卡驱动,我要准备与网络进行通信
//告诉网络驱动,一会儿有给8888端口号的消息,你给我传过来
byte[] data = new byte[1024];
DatagramPacket dp = new DatagramPacket(data,data.length);
//一会儿接收的数据会被放到data数组中
//接收数据
ds.receive(dp);
//拆解数据
int len = dp.getLength();//获取实际接收了几个字节
String str = new String(data,0, len);
System.out.println("接收的消息:" + str);
ds.close();
}
}2.4 基于 TCP 协议编程
案例 1
服务器端
需求:接收客户端的连接,当客户端连接成功后,给客户端发一句话:欢迎登录
package com.atguigu.net.tcp;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.PrintStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Scanner;
public class Server {
public static void main(String[] args)throws Exception {
//1、开启服务器,监听客户端的连接,等待客户端连接
ServerSocket server = new ServerSocket(8888);
//2、接收客户端的连接,一旦有客户端连接进来,就会产生一个Socket对象与这个客户端进行通信
//如果没有客户端连接,这句代码会阻塞,一直等待
Socket socket = server.accept();
//3、按照规则编写代码
/*
规则:
(1)先发还是先收 或 先收后发 (串行) 假设这里选择先收后发
(2)同时发同时收 (并发,多线程)
(3)按行收/发,还是单纯的以字节方式收/发 按行收/发
*/
//收
InputStream stream = socket.getInputStream();
Scanner scanner = new Scanner(stream);
while (scanner.hasNextLine()){
String line = scanner.nextLine();
System.out.println(line);
}
//发
OutputStream outputStream = socket.getOutputStream();
PrintStream ps = new PrintStream(outputStream);
ps.println("欢迎登录!");
//结束的话的释放资源
ps.close();
outputStream.close();
scanner.close();
stream.close();
socket.close();
server.close();
}
}客户端
需求:主动连接服务器端,连接后给服务器发送一句话:你好
package com.atguigu.net.tcp;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.PrintStream;
import java.net.Socket;
import java.util.Scanner;
public class Client {
public static void main(String[] args) throws Exception{
//1、主动连接服务器,必须指定服务器的IP地址和端口号
Socket socket = new Socket("192.168.39.60",8888);
//2、按照规则编写代码
/*
规则:
(1)先发还是先收 或 先收后发 (串行) 假设这里选择先发后收(与服务器对应)
(2)同时发同时收 (并发,多线程)
(3)按行收/发,还是单纯的以字节方式收/发 按行收/发
*/
//发
OutputStream outputStream = socket.getOutputStream();
PrintStream ps = new PrintStream(outputStream);
ps.println("你好!");
ps.println("中午吃什么!");
ps.println("考试准备怎么样了!");
//告诉对方发送完毕了
socket.shutdownOutput();
//收
InputStream stream = socket.getInputStream();
Scanner scanner = new Scanner(stream);
while (scanner.hasNextLine()){
String line = scanner.nextLine();
System.out.println(line);
}
//结束的话的释放资源
ps.close();
outputStream.close();
scanner.close();
stream.close();
socket.close();
}
}案例 2
服务器端
需求:
接收客户端上传的文件,保存到服务器主机的 d:\upload 文件夹中
package com.atguigu.net.tcp2;
import java.net.ServerSocket;
import java.net.Socket;
public class Server {
public static void main(String[] args) throws Exception{
//1、开启服务器,监听客户端的连接,等待客户端连接
ServerSocket server = new ServerSocket(8888);
while(true) {
//2、接收客户端的连接,一旦有客户端连接进来,就会产生一个Socket对象与这个客户端进行通信
//如果没有客户端连接,这句代码会阻塞,一直等待
Socket socket = server.accept();
System.out.println(socket.getInetAddress() +"连接成功");
UploadThread thread = new UploadThread(socket);
thread.start();
}
}
}package com.atguigu.net.tcp2;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.net.Socket;
public class UploadThread extends Thread{
private final Socket socket;
public UploadThread(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
//3、按照规则编写代码
//接收文件内容
FileOutputStream fos = null;
try(
InputStream inputStream = socket.getInputStream();
ObjectInputStream ois = new ObjectInputStream(inputStream);
socket;
) {
String filename = ois.readUTF();
//为了避免文件重名,可以加上时间戳、UUID等
long time = System.currentTimeMillis();
String ip = socket.getInetAddress().getHostAddress();//获取客户端的IP地址
filename = time + "_" + ip + "_" + filename;
fos = new FileOutputStream("d:\\upload\\" + filename);
byte[] data = new byte[1024];
while (true) {
int len = ois.read(data);
if (len == -1) {
break;
}
//写到服务器的本地文件中
fos.write(data, 0, len);
}
fos.flush();
System.out.println("接收完毕!");
}catch (IOException e){
e.printStackTrace();
}finally {
try {
if(fos!=null) {
//释放资源
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}客户端
需求:
客户端从本地选择一个文件,上传到服务器。
package com.atguigu.net.tcp2;
import java.io.File;
import java.io.FileInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.util.Scanner;
public class Client {
public static void main(String[] args) throws Exception{
//1、主动连接服务器
Socket socket = new Socket("192.168.39.60",8888);
//2、在本地选择一个文件
Scanner keyboard = new Scanner(System.in);
System.out.print("请输入你要上传的文件的完整路径名:");
String filepath = keyboard.nextLine();//考虑到有的用户的文件夹名中包含空格,用nextLine()
//D:\temp\img\dog.jpg
File file =new File(filepath);
String filename = file.getName();
//3、给服务器发送文件名.扩展名,例如:dog.jpg
OutputStream outputStream = socket.getOutputStream();
// outputStream.write(filename.getBytes());//对方不方便 区分文件名和内容
ObjectOutputStream oos = new ObjectOutputStream(outputStream);//对象输出流
oos.writeUTF(filename);
oos.flush();//及时写出文件名
//4、先从本地读取文件内容,然后发送到服务器端
FileInputStream fis = new FileInputStream(filepath);
byte[] data = new byte[1024];
while(true){
int len = fis.read(data);
if(len == -1){
break;
}
//发送给服务器
oos.write(data,0,len);
}
System.out.println("上传完毕!");
//释放资源
oos.close();
outputStream.close();
fis.close();
keyboard.close();
socket.close();
}
}2.5 基于 HTTP 协议编程
1、HTTP 简介


HTTP 超文本传输协议(HTTP-Hyper Text transfer protocol),是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于 1990 年提出,经过十几年的使用与发展,得到不断地完善和扩展。它是一种详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。客户端与服务端通信时传输的内容我们称之为**报文。HTTP协议规定了报文的格式,即规定了客户端发送给服务器的报文格式,也规定了服务器发送给客户端的报文格式。客户端发送给服务器的称为"请求报文",服务器发送给客户端的称为"响应报文"**。
2、HTTP 协议的会话方式
客户端(通常是浏览器,但是也可以是其他形式的客户端)与服务器之间的通信过程要经历四个步骤。

- 客户端与服务器的连接过程是短暂的,每次连接只处理一个请求和响应。对每一个资源的访问,客户端与 WEB 服务器都要建立一次单独的连接。
- 客户端到服务器之间的所有通讯都是完全独立分开的请求和响应对。
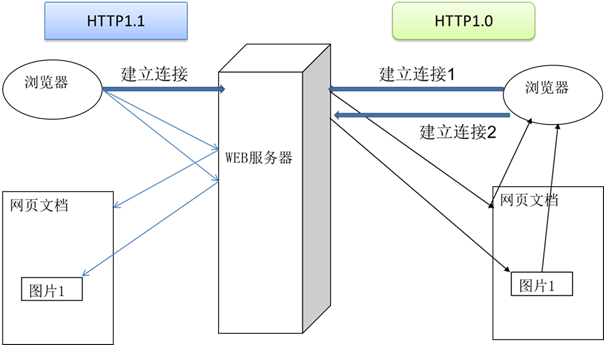
3、HTTP1.0 和 HTTP1.1 的区别
在 HTTP1.0 版本中,浏览器请求一个带有图片的网页,会由于下载图片而与服务器之间开启一个新的连接;但在 HTTP1.1 版本中,允许浏览器在拿到当前请求对应的全部资源后再断开连接,提高了效率。
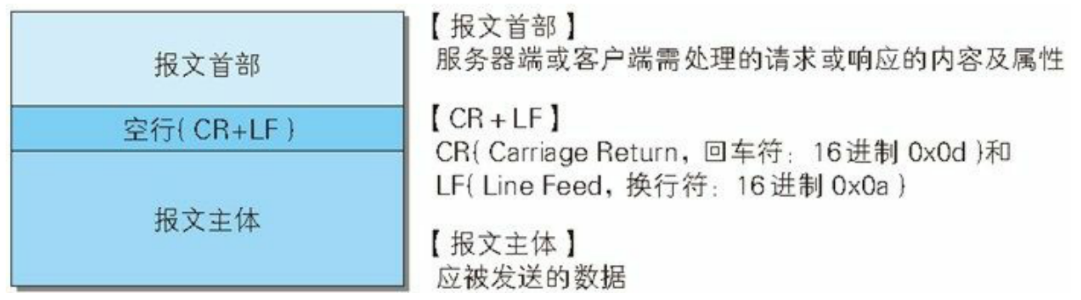
4、请求和响应报文的格式
主体上分为报文首部和报文主体,中间空行隔开:
报文首部可以继续细分为 "行" 和 "头":
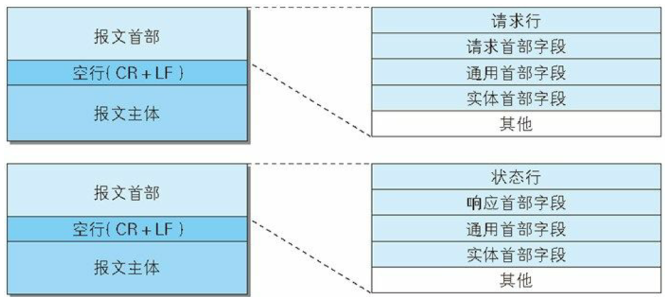
请求报文格式:
- 请求首行(请求行); GET/POST 资源路径?参数 HTTP/1.1
- 请求头信息(请求头);
- 空行;
- 请求体;
其中:
- 请求行中包含 请求方式 、资源路径 、协议及版本。例如:GET /demo?user=admin HTTP/1.1
- 只有客户端发起 POST 请求并携带请求数据,请求体中才能内容
响应报文格式:
- 响应首行(响应行); 协议/版本 状态码 状态码描述
- 响应头信息(响应头);
- 空行;
- 响应体;
其中:
- 响应行中包括 协议及版本、响应状态码、状态描述。例如:HTTP/1.1 200 OK
- 响应体:具体响应内容
- 响应码对浏览器来说很重要,它告诉浏览器响应的结果。比较有代表性的响应码如下:
- 200: 请求成功,浏览器会把响应体内容(通常是 html)显示在浏览器中;
- 302: 重定向,当响应码为 302 时,表示服务器要求浏览器重新再发一个请求,服务器会发送一个响应头 Location 指定新请求的 URL 地址;
- 304: 使用了本地缓存;
- 404: 请求的资源没有找到,说明客户端错误的请求了不存在的资源;
- 405: 请求的方式不允许;
- 500: 请求资源找到了,但服务器内部出现了错误;
- 更多响应码请看https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Reference/Status
三、langchain4j
3.1 简介
LangChain4j 是一个专为 Java 开发者设计的开源库,旨在简化大型语言模型(LLM)在 Java 应用程序中的集成过程。它于 2023 年初开发,灵感来源于 Python 和 JavaScript 的 LLM 生态,旨在填补 Java 生态在 AI 应用开发中的空白。
核心功能
- 统一 API 接口 LangChain4j 提供了标准化的 API,支持 15+ 主流 LLM 提供商(如 OpenAI、Google Gemini、阿里通义、智谱 AI 等)和 15+ 向量数据库(如 Pinecone、Milvus、Qdrant 等),开发者可以轻松切换模型或存储而无需重写代码。
- 综合工具箱
- 低级功能:提示模板、聊天记忆管理、输出解析等。
- 高级功能:AI 服务(如
AiServices)、RAG(检索增强生成)、动态工具调用等。 多模态支持:可处理文本、图像、音频等输入。
- 模块化设计
-core:定义核心抽象(如ChatLanguageModel、EmbeddingStore)。langchain4j-{integration}:提供与不同 LLM 和向量数据库的集成。
优势
- 简化 Java AI 开发:通过 Spring Boot 和 Quarkus(夸克) 集成,降低 LLM 接入门槛。
- 高性能:相比 Python 方案,Java 版本在吞吐量、内存优化和冷启动时间上表现更优。
- 企业级适配:支持 PDF 解析、合同分析、知识图谱构建等业务场景。
3.2 调用本地 AI 大模型(了解)
1、依赖
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-ollama -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>0.36.2</version>
</dependency>
<!-- 以下日志的依赖最好加上,因为当连接失败时,会触发日志记录的相关代码 -->
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-simple -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.13</version>
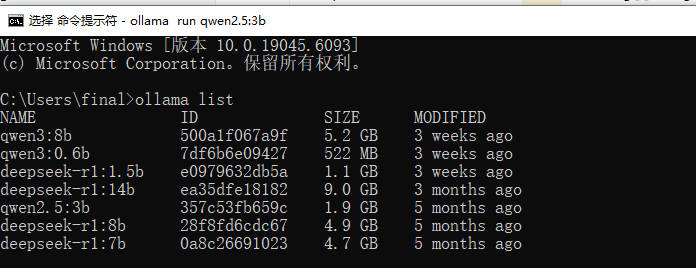
</dependency>2、启动 ollama,查看本地有哪些大模型
注意:Ollama 启动后才能使用本地模型
3、示例代码
package com.atguigu.ai;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.ollama.OllamaChatModel;
import dev.langchain4j.model.output.Response;
public class TestOllama {
public static void main(String[] args) {
OllamaChatModel chatModel = OllamaChatModel.builder()
.baseUrl("http://localhost:11434")
.modelName("qwen2.5:3b")
.build();
UserMessage userMessage = UserMessage.from("你好,你是谁");
//HTTP协议的交互方式:请求-响应
Response<AiMessage> response = chatModel.generate(userMessage);
*//*
UserMessage:代表用户向AI发起的提问
AiMessage:AI响应的结果
*//*
AiMessage aiMessage = response.content();
String content = aiMessage.text();
System.out.println("AI回答:" + content);
}
}3.2 调用云端 AI 大模型(掌握)
3.2.1 依赖
注意此时要将调用本地大模型的 langchain4j-ollama 依赖去掉,否则冲突
<!--调用ollama本地部署的大模型-->
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-ollama -->
<!-- <dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>0.36.2</version>
</dependency>-->
<!-- 以下日志的依赖最好加上,因为当连接失败时,会触发日志记录的相关代码 -->
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-simple -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.13</version>
</dependency>
<!--调用云端AI大模型-->
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-open-ai -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.1.0</version>
</dependency>3.2.2 配置 API-Key 的环境变量
如果通过代码调用模型,建议您配置 API Key 到环境变量,以便在调用模型或应用时使用。这样可以避免在代码中显式地配置 API Key,从而降低 API Key 泄漏的风险。例如:
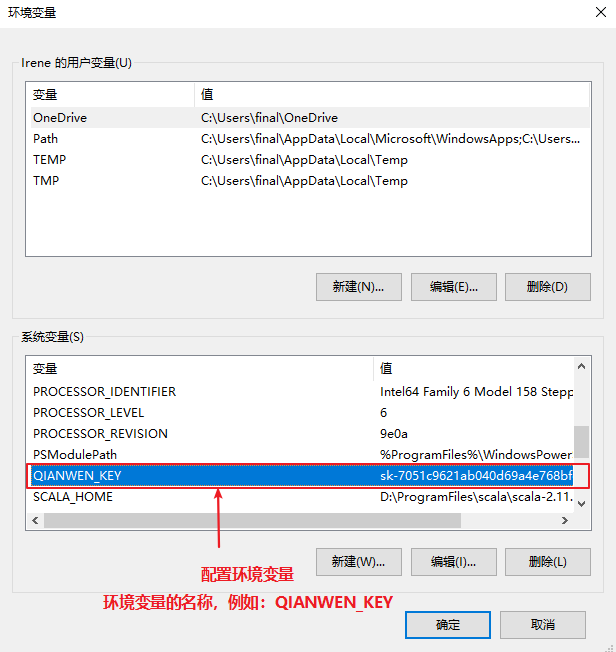
package com.atguigu.ai;
public class TestEnv {
public static void main(String[] args) {
//如果IDEA启动后,才配置的环境变量,那么需要重启IDEA,才能读取到
String qianwenKey = System.getenv("QIANWEN_KEY");
System.out.println("qianwenKey = " + qianwenKey);
}
}3.2.3 查看所要调用大模型的名称和 url
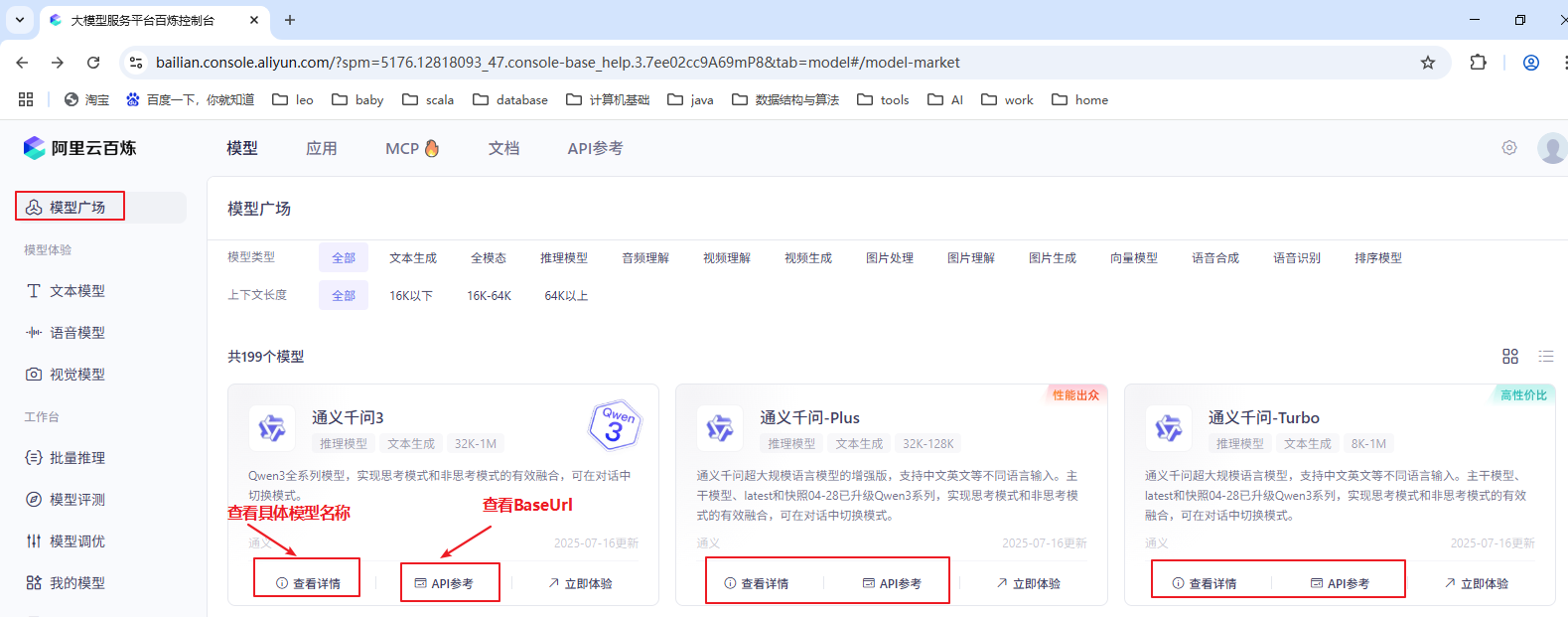
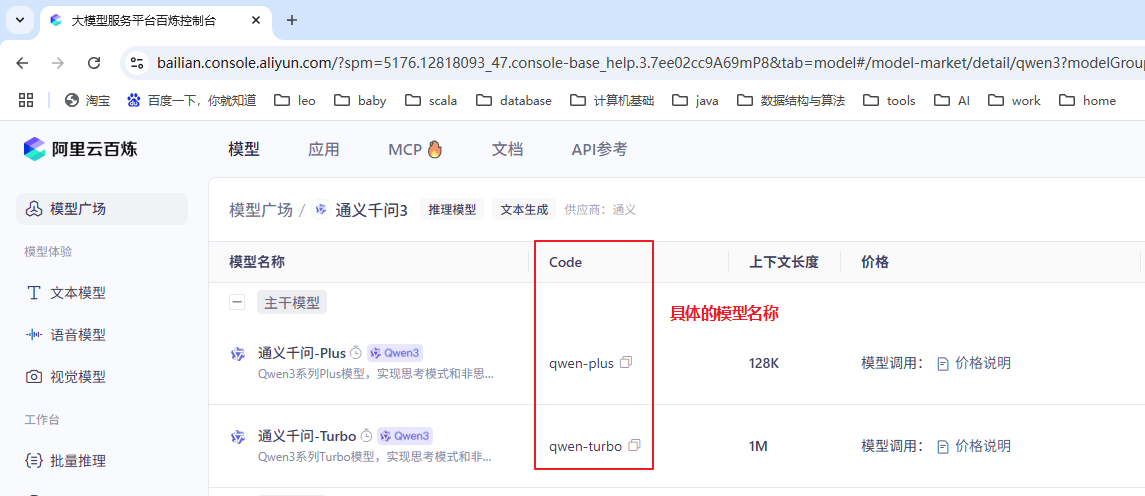
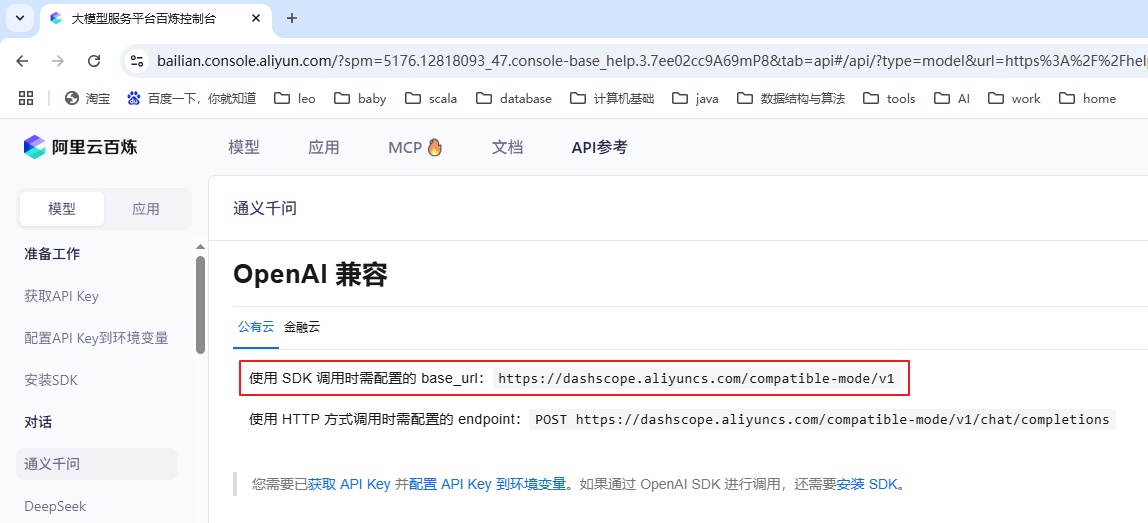
调用大模型通常需要输入三个信息:
- 获取的 API Key
- Base URL:如
https://dashscope.aliyuncs.com/compatible-mode/v1 - 模型名称,如 qwen-plus
3.3.4 示例代码
package com.atguigu.ai;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.response.ChatResponse;
import dev.langchain4j.model.openai.OpenAiChatModel;
public class TestCloud {
public static void main(String[] args) {
/*
访问云端的大模型,需要三要素:
(1)url :https://dashscope.aliyuncs.com/compatible-mode/v1
(2)大模型名称 :qwen-plus
(3)api-key
*/
String apiKey = System.getenv("QIANWEN_KEY");
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("qwen-plus")
.apiKey(apiKey)
.build();
UserMessage userMessage = UserMessage.from("你好,你是谁?");
ChatResponse chatResponse = chatModel.chat(userMessage);
AiMessage aiMessage = chatResponse.aiMessage();
String content = aiMessage.text();
System.out.println("AI回答: " + content);
}
}四、谷语 AI 聊天项目
4.1 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>chat</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- 以下日志的依赖最好加上,因为当连接失败时,会触发日志记录的相关代码 -->
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-simple -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.13</version>
</dependency>
<!--调用云端AI大模型-->
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-open-ai -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>
</project>4.2 ai.properties
apiKeyName=QIANWEN_KEY
baseUrl=https://dashscope.aliyuncs.com/compatible-mode/v1
modelName=qwen-plus
messageDir=d:\\message4.3 ChatService
package com.atguigu.service;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.SystemMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.response.ChatResponse;
import dev.langchain4j.model.openai.OpenAiChatModel;
import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Properties;
import java.util.Scanner;
public class ChatService {
private static OpenAiChatModel chatModel;
private static ArrayList<ChatMessage> chatMessages = new ArrayList<>();
private static ArrayList<ChatMessage> summaryMessages = new ArrayList<>();
private static final int MAX_COUNT = 10;
private static String title;
private static String messageDir;
/*
摘要:提取前面的聊天记录的关键信息,汇总成一条摘要。chatMessages里面有MAX_COUNT记录,就生成一个摘要。
摘要仍然让AI帮我们生成。
*/
static {
try {
//静态代码块
Properties properties = new Properties();
ClassLoader classLoader = ChatService.class.getClassLoader();
properties.load(classLoader.getResourceAsStream("ai.properties"));
String apiKeyName = properties.getProperty("apiKeyName");
String apiKey = System.getenv(apiKeyName);
String baseUrl = properties.getProperty("baseUrl");
String modelName = properties.getProperty("modelName");
messageDir = properties.getProperty("messageDir");
chatModel = OpenAiChatModel.builder()
.apiKey(apiKey)
.baseUrl(baseUrl)
.modelName(modelName)
.build();
} catch (IOException e) {
e.printStackTrace();
}
}
public static String chat(String question) throws IOException {
//第一个问题的前10个字通常可以作为文件标题
if(title==null){
String str = question;
str = str.replaceAll("[^\\u4e00-\\u9fffa-zA-Z0-9]","");
if(str.length()>10){
str = str.substring(0,10);
}
title = str + ".txt";
}
if(chatMessages.size() >= MAX_COUNT){
//生成摘要
generateSummary();
//存储聊天记录
saveChatRecords();
//chatMessages集合中的聊天记录已经生成摘要,可以从chatMessages里面删除了
chatMessages.clear();
}
UserMessage userMessage = UserMessage.from(question);
chatMessages.add(userMessage);//添加本次用户问题
ArrayList<ChatMessage> list = new ArrayList<>();
list.addAll(chatMessages);//用户问题 + AI回答
list.addAll(summaryMessages);//纯摘要
//本次聊天发送给AI有(1)最近的10条之内的聊天记录(2)之前旧聊天记录的摘要
ChatResponse chatResponse = chatModel.chat(list);//发送整个集合
AiMessage aiMessage = chatResponse.aiMessage();
chatMessages.add(aiMessage);//添加AI回答
return aiMessage.text();
}
private static void generateSummary() {
//优化思路:精简摘要(1)去掉之前的摘要(2)给AI的提示词上下功夫,简化
//优化思路:(1)把生成摘要的代码放到一个独立的线程中(2)把保存历史记录的代码放到一个独立的线程中
new Thread(){
@Override
public void run() {
SystemMessage systemMessage = SystemMessage.from("你是一个小助手,帮我整理一下这些聊天记录的摘要,尽量用精简的话或几个关键字总结摘要");
ArrayList<ChatMessage> list = new ArrayList<>();
list.add(systemMessage);
list.addAll(chatMessages);
list.addAll(summaryMessages);
ChatResponse chatResponse = chatModel.chat(list);
AiMessage aiMessage = chatResponse.aiMessage();
summaryMessages.clear();//可选。有的同学认为,生成摘要时,已经包含之前的摘要内容,没必要保留之前的摘要内容了。
summaryMessages.add(aiMessage);//记录AI返回的摘要
}
}.start();
}
public static void saveChatRecords() {
new Thread(){
@Override
public void run() {
try(
FileOutputStream fos = new FileOutputStream(messageDir + "\\" + title,true);
PrintStream ps = new PrintStream(fos);
){
for (ChatMessage chatMessage : chatMessages) {
if (chatMessage instanceof UserMessage u) {
ps.println("我:" + u.singleText());
} else if (chatMessage instanceof AiMessage a) {
ps.println("AI:" + a.text());
}
}
}catch(IOException e){
e.printStackTrace();
}
}
}.start();
}
public static ArrayList<File> listAllHistories(){
File dir = new File(messageDir);
File[] files = dir.listFiles();
ArrayList<File> allFiles = new ArrayList<>();
Collections.addAll(allFiles, files);
return allFiles;
}
public static void generateHistorySummary(File file){
ArrayList<ChatMessage> list = new ArrayList<>();
StringBuilder builder = new StringBuilder();
boolean flag = true;
boolean role = true;//true代表用户,false代表ai
try(Scanner scanner = new Scanner(file);) {
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
if(line.startsWith("我:")){
if(!flag) {
AiMessage aiMessage = AiMessage.from(builder.toString());
list.add(aiMessage);
}
builder = new StringBuilder();
role = true;
}else if(line.startsWith("AI:")){
if(!flag) {
UserMessage userMessage = UserMessage.from(builder.toString());
list.add(userMessage);
}
builder = new StringBuilder();
role = false;
}
builder.append(line);
flag = false;
}
if(role) {
UserMessage userMessage = UserMessage.from(builder.toString());
list.add(userMessage);
}else{
AiMessage aiMessage = AiMessage.from(builder.toString());
list.add(aiMessage);
}
SystemMessage systemMessage = SystemMessage.from("你是一个小助手,帮我整理一下这些聊天记录的摘要,尽量用精简的话或几个关键字总结摘要");
list.add(systemMessage);
ChatResponse chatResponse = chatModel.chat(list);
AiMessage aiMessage = chatResponse.aiMessage();
summaryMessages.clear();//可选。有的同学认为,生成摘要时,已经包含之前的摘要内容,没必要保留之前的摘要内容了。
summaryMessages.add(aiMessage);//记录AI返回的摘要
title = file.getName();
}catch (IOException e){
e.printStackTrace();
}
}
}4.4 ChatView
package com.atguigu.view;
import com.atguigu.service.ChatService;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Scanner;
public class ChatView {
private static Scanner input = new Scanner(System.in);
public static void main(String[] args) throws IOException {
boolean flag = true;
while (flag) {
System.out.println("================欢迎使用谷语聊天工具====================");
System.out.println("\t\t\t\t1、查看历史聊天记录");
System.out.println("\t\t\t\t2、开启新对话");
System.out.println("\t\t\t\t3、退出");
System.out.print("\t\t\t\t请选择:");
int select = input.nextInt();
input.nextLine();//读取整数后面的回车符
switch (select) {
case 1 -> history();
case 2 -> chat();
case 3 -> {
ChatService.saveChatRecords();
flag = false;
}
}
}
}
public static void history() throws IOException {
//读取所有聊天记录的文件的列表
ArrayList<File> files = ChatService.listAllHistories();
for(int i=0; i<files.size(); i++){
System.out.println((i+1) + "." + files.get(i).getName());
}
//选择你要哪个聊天记录
System.out.print("请选择你要查看哪个文件(填写编号):");
int id = input.nextInt();
input.nextLine();
//显示某个聊天记录的文件内容
File file = files.get(id-1);
Scanner scanner = new Scanner(file);
while(scanner.hasNextLine()){
String line = scanner.nextLine();
System.out.println(line);
}
System.out.println();
System.out.println();
System.out.print("是否基于当前聊天记录继续聊(Y:继续,N:返回主菜单)");
String confirm = input.nextLine();
if("N".equalsIgnoreCase(confirm)){
return;
}else{
//....
//把之前的聊天记录生成一个摘要
ChatService.generateHistorySummary(file);
//开启新对话
chat();
}
}
public static void chat() throws IOException {
while(true){
System.out.print("请输入你要问的问题:");
String question = input.nextLine().trim();
if("bye".equalsIgnoreCase(question)){
System.out.println("谢谢使用谷语AI聊天程序!");
break;
}
if(question.isBlank()){
System.out.println("提问不能为空!");
continue;
}
String answer = ChatService.chat(question);
System.out.println("AI回答:" + answer);
}
}
}