一、复习
1.1 Collection 根接口的方法(通用的增删改查遍历的操作)
添加:add、addAll
删除:remove、removeAll、removeIf、retainAll、clear
修改:无
查询:size、contains、containsAll、isEmpty
遍历:增强 for 循环、forEach 方法、Iterator 迭代器
上面这些方法都没有下标信息
1.2 List 比 Collection 要多一些方法
添加:add(下标,元素)、addAll(下标,一组元素)
删除:remove(下标)
修改:set(下标,新元素)、replaceAll(UnaryOperator 接口的实现类对象)、sort
查询:indexOf、lastIndexOf、
subList(起始下标,终止下标)、get(下标)遍历:普通 for 循环、ListIterator 列表迭代器
1.3 List 与 Set 的区别
Set:不可重复、无序
List:可重复、有序
1.4 几种 Set 的区别
HashSet:存、取顺序不一致,无规律
LinkedHashSet:存、取顺序一致,按照添加顺序排列,因为它内部有 Linked 链表记录顺序
TreeSet:按照元素的大小顺序排。必须依赖于 Comparable 或 Comparator 接口
HashSet 和 LinkedHashSet 它们依据元素的 hashCode 和 equals 方法来叛别元素是否重复。TreeSet 依据元素大小来判断元素是否重复,只要比较器认为两个元素相等(比较结果是 0)就认为元素重复。
1.5 学习集合有 3 个或 4 个层次
- 熟悉各种集合的 API 操作(各种方法)
- 熟悉各种集合的区别(例如:List 和 Set 区别、3 种 Set 区别)
- 尽量会分析一些核心操作的源码,原理
- 模仿核心类库的这些集合实现一些与他们类似或其他集合类型
1.6 泛型
1、泛型类或泛型接口的使用
以 ArrayList
<E>为例,它创建对象时:
javaArrayList<具体类型> 变量名 = new ArrayList<>();继承 ArrayList
<E>,javapublic class 子类 extends ArrayList<具体类型>{ ..}javapublic class 子类<字母T> extends ArrayList<字母T>{ ..}
以 Comparable
<T>为例- 实现接口:
javapublic class 子类 implements Comparable<子类名 或 子类的父类>{ ..}以 Comparator
<T>为例匿名内部类实现接口:
javaComparator<具体类型> 变量名 = new Comparator<>{ public int compare(具体类型 t1, 具体类型 t2){ //.... } }
2、泛型方法
语法格式:
【修饰符】 class 类名{
【修饰符】 <泛型字母列表> 返回值类型 方法名(【形参列表】)【throws 异常类型列表】{
}
}调用一个泛型方法的格式:正常调用
以Arrays类:public static <T> List<T> asList(T... a) 为例List<String> list1 = Arrays.asList("hello","java"); //T由 "hello"等实参的类型自动推断是String
List<Integer> list2 = Arrays.asList(1,2,3,4);//T由 1,2等实参的类型自动推断是Integer
List<Integer> list2 = Arrays.asList("hello","java",1,2,3,4);//T由 1,2、"hello"等实参的类型共同推断,找它们的公共的父类或父接口,Object或Serializable、Comparable、Constable等3、通配符
- 泛型类
<?>:?代表任意引用数据类型- 如果是集合
<?>,那么这个集合只能查看元素,不能添加元素
- 如果是集合
- 泛型类
<? extends 上限>:?要求是上限或上限的子类- 如果是集合
<? xtends 上限>,那么这个集合只能查看元素,不能添加元素
- 如果是集合
- 泛型类
<? super 下限>:?要求是下限或下限的父类- 如果是集合
<? super 下限>,那么这个集合可以添加元素,但是只能添加下限或下限的子类对象
- 如果是集合
以ArrayList<E>为例:
ArrayList<?> list1 = new ArrayList<Object>();
ArrayList<?> list2 = new ArrayList<String>();
ArrayList<?> list3 = new ArrayList<Number>();
ArrayList<?> list4 = new ArrayList<Integer>();
ArrayList<?> list5 = new ArrayList<Double>();
ArrayList<? extends Number> list1 = new ArrayList<Object>();//错误
ArrayList<? extends Number> list2 = new ArrayList<String>();//错误
ArrayList<? extends Number> list3 = new ArrayList<Number>();
ArrayList<? extends Number> list4 = new ArrayList<Integer>();
ArrayList<? extends Number> list5 = new ArrayList<Double>();
ArrayList<? super Number> list1 = new ArrayList<Object>();
ArrayList<? super Number> list2 = new ArrayList<String>();//错误
ArrayList<? super Number> list3 = new ArrayList<Number>();
ArrayList<? super Number> list4 = new ArrayList<Integer>();//错误
ArrayList<? super Number> list5 = new ArrayList<Double>();//错误答疑: ArrayList<?> 、 ArrayList<? extends Number>、 ArrayList<? super Number>是否可以添加元素二、Collection 集合(续)
2.1 List 系列的集合有哪些实现类(掌握)
- ArrayList(使用频率最高):它是一个动态数组
- Vector:它也是一个动态数组
- LinkedList(现在来说使用频率不高,但是它是一种经典的数据结构,有必要了解它):它是一个双向链表
- Stack:它是一个栈结构的集合,它是 Vector 的子类。Stack 增加了几个方法,专门凸显栈结构的操作特点:先进后出(FILO:First In Last Out,或 LIFO ,Last In First Out 后进先出)。
push(元素):把元素压入栈顶pop():返回栈顶元素,弹走栈顶元素peek():查看栈顶元素,但不弹走search(元素):查看元素的位置
ArrayList 和 Vector 的区别?
Vector:
- 古老的(命名不统一);
线程安全的,效率低;- 扩容机制:默认是
2倍(优点:扩容频率低,不用老搬家,缺点:空间利用率低,可能浪费)- 如果 new
Vector(),默认容量是 10,当然可以直接指定需要的容量 newVector(容量)- Vector 可以手动指定增量
ArrayList:
- 较新的(命名风格统一,以 List 结尾);
线程不安全的,效率高;- 扩容机制:默认是
1.5倍(优点:空间利用率高,浪费的少,缺点:扩容频率高,总搬家)- 如果 new
ArrayList(),默认容量是 0。当第一次添加元素时,会把数组长度初始化为 10。当然可以直接指定需要的容量 newArrayList(容量)- ArrayList 是无法手动指定增量的
为什么 new
ArrayList(),默认容量是 0???为什么不和 Vector 一样直接 10???因为我们有可能创建完集合之后,不放元素。可以避免不必要的浪费。当你真的 add 时,说明确实需要放元素,再创建实际的数组。
顺便回忆:字符串缓冲区、可变字符串
StringBuffer:古老的,线程安全的,效率低
StringBuilder:较新的,线程不安全,效率高
动态数组与双向链表有什么区别?
动态数组:
- 它的物理结构是数组,它的元素是连续存储的,需要开辟一整块连续的存储空间。
- 优势:根据下标访问元素的效率极高,时间复杂度是
O(1)- 缺点:
- 对内存的连续性要求更高,对 GC 回收的要求更高,因为需要分配一整块连续空间。
- 如果非末尾位置添加和删除,需要移动元素。好在现在的 JVM,内存拷贝技术的效率非常高。
- 动态数组总是会涉及到扩容、搬家的问题。
双向链表:
- 它的物理结构是链表,它的元素通常都是不连续
- 缺点:无论是不是根据下标访问,时间复杂度是
O(n)。链表结构需要结点来辅助,结点对象的创建、回收比较耗时耗力。- 优点:对内存的连续性要求低
说明:网上有不同的答案,关于动态数组与双向链表谁的效率高的问题?
如果是 C 语言来实现,因为不涉及到创建对象的问题,那么双向链表效率高,因为它不用扩容,不用移动元素。
如果是 Java 语言来实现,因为涉及到结点对象的创建回收问题,那么动态数组反而效率更高。
package com.atguigu.list;
import org.junit.jupiter.api.Test;
import java.util.*;
/*
问题1:测试类的名字是不是有什么说道?
按照企业中开发规范来说,建议 TestXxx,或 XxxTest, 或XxxTestCase 等
问题2:咱们现在已经用maven,有专门的test目录(文件夹),那么这些Test测试类,是不是放到test目录下更好一点?
按照企业的实际项目来说,确实如此。
*/
public class TestList {
@Test
public void test1(){
ArrayList<String> list = new ArrayList<>();
list.add("hello");
Vector<String> vector = new Vector<>(20,5);
vector.add("hello");
System.out.println(list);
System.out.println(vector);
}
@Test
public void test2(){
long start = System.currentTimeMillis();//获取时间戳
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
Random random = new Random();
for(int i=1; i<=100000; i++){
int index = random.nextInt(0,list.size());
list.add(index, i);
}
long end = System.currentTimeMillis();//获取时间戳
System.out.println("耗时:" + (end-start));//耗时:263
}
@Test
public void test3(){
long start = System.currentTimeMillis();//获取时间戳
LinkedList<Integer> list = new LinkedList<>();
list.add(1);
Random random = new Random();
for(int i=1; i<=100000; i++){
int index = random.nextInt(0,list.size());
list.add(index, i);
}
long end = System.currentTimeMillis();//获取时间戳
System.out.println("耗时:" + (end-start));//耗时:20749
}
@Test
public void test4(){
Stack<String> stack = new Stack<>();
stack.push("熊大");
stack.push("熊二");
stack.push("光头强");
stack.push("肥波");
System.out.println(stack.pop());//肥波
System.out.println(stack.pop());//光头强
System.out.println(stack.pop());//熊二
System.out.println(stack.pop());//熊大
System.out.println(stack.pop());//java.util.EmptyStackException空栈异常
//先进后出,或后进先出
}
@Test
public void test5(){
Stack<String> stack = new Stack<>();
stack.push("熊大");
stack.push("熊二");
stack.push("光头强");
stack.push("肥波");
while(!stack.isEmpty()){
System.out.println(stack.pop());
}
//先进后出,或后进先出
}
@Test
public void test6(){
Stack<String> stack = new Stack<>();
stack.push("熊大");
stack.push("熊二");
stack.push("光头强");
stack.push("肥波");
System.out.println(stack.peek());//肥波
System.out.println(stack.peek());//肥波
System.out.println(stack.peek());//肥波
}
@Test
public void test7(){
ArrayList<String> stack = new ArrayList<>();
stack.add("熊大");
stack.add("熊二");
stack.add("光头强");
stack.add("肥波");
//先进后出
while(!stack.isEmpty()){
System.out.println(stack.remove(stack.size()-1));
}
}
}2.2 动态数组部分功能(自我挑战)
分析请看《尚硅谷Java 基础第 11 章_集合原理分析(1)动态数组.pptx》
package com.atguigu.list;
import java.util.Arrays;
import java.util.Objects;
//<E>代表将来存到集合中的元素的类型
public class MyArrayList<E> {
private Object[] elements= new Object[10];
private int size;//代表实际元素的个数
public void add(E e){//末尾位置添加
//抽取一段代码构成一个新方法的快捷键是Ctrl + Alt + M
grow();
elements[size++] = e;
}
private void grow() {
if(size >= elements.length){
//扩容
// elements = Arrays.copyOf(elements, elements.length + 1);//一次增加1个,频率非常高
// elements = Arrays.copyOf(elements, elements.length*2);//2倍扩容
// elements = Arrays.copyOf(elements, elements.length<<1);//2倍扩容
// elements = Arrays.copyOf(elements, elements.length + elements.length/2);//1.5倍扩容
elements = Arrays.copyOf(elements, elements.length + (elements.length>>1));//1.5倍扩容
}
}
public void add(int index, E e){//插入
//添加时 index的位置必须是 [0, size]
if(index<0 || index>size){
throw new IndexOutOfBoundsException();
}
//可能需要扩容
grow();
//[index, size-1]范围的元素需要右移
/*
假设: elements的长度是10, size = 5, index = 1
需要移动的元素:[1][2][3][4]
移动size-index
elements的长度是10, size = 7, index = 3
需要移动的元素:[3][4][5][6]
移动size-index
*/
System.arraycopy(elements, index, elements, index+1, size-index);
//新元素放到index位置
elements[index] = e;
//元素个数增加
size++;
}
public void remove(int index){//删除[index]位置的元素
//删除时 index的位置必须是 [0, size-1]
if(index<0 || index>=size){
throw new IndexOutOfBoundsException();
}
//[index, size-1]范围的元素要左移
/*
假设: elements的长度是10, size = 5, index = 1
需要移动的元素:[2][3][4]
移动size-index-1
elements的长度是10, size = 7, index = 3
需要移动的元素:[4][5][6]
移动size-index-1
*/
System.arraycopy(elements, index+1, elements, index, size-index-1);
//元素个数减少
size--;
}
public void remove(Object target) {
//查找target在数组的位置
int index = indexOf(target);
if(index != -1) {
remove(index);
}
}
public int indexOf(Object target){
/* if(target == null){
for (int i = 0; i < elements.length; i++) {
if(elements[i] == target){
return i;
}
}
}else {
//返回target在数组中的下标,找到返回下标,没找到返回-1
for (int i = 0; i < elements.length; i++) {
// if(elements[i] == target){//太严格了,比较地址值
if (target.equals(elements[i])) {
return i;
}
}
}*/
for (int i = 0; i < elements.length; i++) {
if (Objects.equals(elements[i], target)) {
return i;
}
}
return -1;
}
@Override
public String toString() {
/*return "MyArrayList{" +
"elements=" + Arrays.toString(elements) +
", size=" + size +
'}';*/
//Arrays.copyOf(elements,size) 复制size个元素
// Arrays.toString(数组)把数组的元素拼接为[元素1,元素2]
return Arrays.toString(Arrays.copyOf(elements,size));
}
}package com.atguigu.list;
import org.junit.jupiter.api.Test;
public class TestMyArrayList {
@Test
public void test1(){
MyArrayList<String> list = new MyArrayList<>();
for(int i=1; i<=13; i++){
list.add("张三" + i);
}
list.remove(1);//张三2没了
list.remove(5);//张三7没了
list.remove("张三8");
System.out.println(list);
}
@Test
public void test2(){
MyArrayList<String> list = new MyArrayList<>();
list.add("hello");
list.add(null);//把null当元素
list.add("world");
list.remove("world");
System.out.println(list);
}
@Test
public void test3(){
MyArrayList<String> list = new MyArrayList<>();
list.add("hello");
list.add(null);//把null当元素
list.add("world");
list.remove(null);
System.out.println(list);
}
}2.3 双向链表的部分功能(自我挑战)
分析请看《尚硅谷Java 基础第 11 章_集合原理分析(2)双向链表.pptx》
package com.atguigu.list;
import java.util.Objects;
import java.util.StringJoiner;
//<E>代表将来存到集合中的元素的类型
public class MyLinkedList<E> {
private int size;//元素个数
private Node<E> first;//头结点,默认值是null
private Node<E> last;//尾结点,默认值是null
//结点类型(因为这个结点类型只为当前MyLinkedList类服务,所以我把它定义为内部类更合适,遵循高内聚的开发原则)
//遵循封装原则,这个内部类用private修饰,对外部不可见
private class Node<E> {
Node<E> previous;//上一个
E data;//元素本身
Node<E> next;//下一个
//它是 构造器,用来创建结点Node的对象
Node(Node<E> previous, E data, Node<E> next) {
this.previous = previous;
this.data = data;
this.next = next;
}
}
public void add(E e){//尾插法,新节点插入到链表的尾部
//1、先创建一个新结点
// Node<E> newNode = new Node<>(新结点的上一个结点,当前结点的元素,新结点的下一个结点);
Node<E> newNode = new Node<>(last, e, null);
//last代表原链表的最后一个结点,那么新结点的上一个结点就是原来链表的最后一个结点
//2、分情况讨论
if(first == null){//链表原来是空的
first = newNode;
}else{
last.next = newNode;
}
//3、新的结点成为链表的最后一个结点
last = newNode;
//4、元素个数增加
size++;
}
public void remove(Object target){
Node<E> node = findNode(target);
if(node == null){//没找到
return;//提前结束,代表不删除
}
Node<E> before = node.previous;
Node<E> after = node.next;
if(before == null){//删除的是第一个结点
first = after;
}else {
before.next = after;
}
if(after == null){
last = before;
}else {
after.previous = before;
}
node.previous = null;
node.next = null;
node.data = null;
size--;
}
private Node<E> findNode(Object target){
Node<E> node = first;
while(node!=null){
if(Objects.equals(node.data, target)){
return node;
}
node = node.next;
}
return null;
}
@Override
public String toString() {
StringJoiner joiner = new StringJoiner(",", "[","]");
Node<E> node = first;
while(node!=null){
joiner.add(node.data.toString());
node = node.next;//往右移动
}
return joiner.toString();
}
}package com.atguigu.list;
import org.junit.jupiter.api.Test;
public class TestMyLinkedList {
@Test
public void test1(){
MyLinkedList<String> list = new MyLinkedList<>();
list.add("hello");
list.add("world");
list.add("java");
list.add("atguigu");
System.out.println(list);
list.remove("hello");
System.out.println(list);
list.remove("java");
System.out.println(list);
list.remove("atguigu");
System.out.println(list);
}
}2.4 队列
Queue 接口是 Collection 的子接口,这个系列的集合称为队列。队列结构的特点:先进先出(FIFO:First In First Out)。

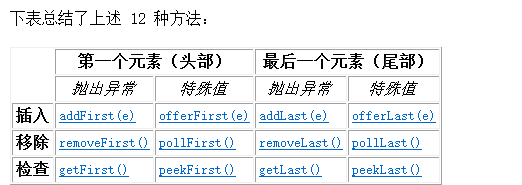
上面 2 组方法分别为失败抛出异常和失败返回特殊值,例如:队列中添加新元素失败时,add 方法就会抛出异常,而 offer 方法就会返回特殊值 false。
Queue 接口,有一个子接口 Deque。支持在两端插入和移除元素。名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。
Queue 接口的实现类很多,通常都是以 Queue 结尾,但是有一个特殊的 LinkedList 没有以 Queue 结尾。LinkedList 是 Deque 的实现类。
package com.atguigu.queue;
import org.junit.jupiter.api.Test;
import java.util.LinkedList;
public class TestQueue {
@Test
public void test1(){
LinkedList<String> queue = new LinkedList<>();
//大部分队列,添加没有数量的限制,但是有些队列是有上限的
queue.add("hello");
queue.add("java");
queue.add("world");
//add默认添加到队尾
//移除的是队头元素,体现先进先出
System.out.println(queue.remove());//hello
System.out.println(queue.remove());//java
System.out.println(queue.remove());//world
System.out.println(queue.remove());//java.util.NoSuchElementException
}
@Test
public void test2(){
LinkedList<String> queue = new LinkedList<>();
//大部分队列,添加没有数量的限制,但是有些队列是有上限的
queue.offer("hello");
queue.offer("java");
queue.offer("world");
//offer默认添加到队尾
//移除的是队头元素,体现先进先出
System.out.println(queue.poll());//hello
System.out.println(queue.poll());//java
System.out.println(queue.poll());//world
System.out.println(queue.poll());//null
}
@Test
public void test3(){
LinkedList<String> queue = new LinkedList<>();
queue.addFirst("hello");
queue.addFirst("java");
queue.addLast("world");
queue.addLast("chai");
//队伍(头) java hello world chai (尾)
System.out.println(queue.removeFirst());//java
System.out.println(queue.removeFirst());//hello
System.out.println(queue.removeFirst());//world
System.out.println(queue.removeFirst());//chai
}
@Test
public void test4(){
LinkedList<String> queue = new LinkedList<>();
queue.addFirst("hello");
queue.addFirst("java");
queue.addLast("world");
queue.addLast("chai");
//队伍(头) java hello world chai (尾)
System.out.println(queue.removeFirst());//java
System.out.println(queue.removeLast());//chai
System.out.println(queue.removeFirst());//hello
System.out.println(queue.removeLast());//world
}
}2.5 Collection 系列集合
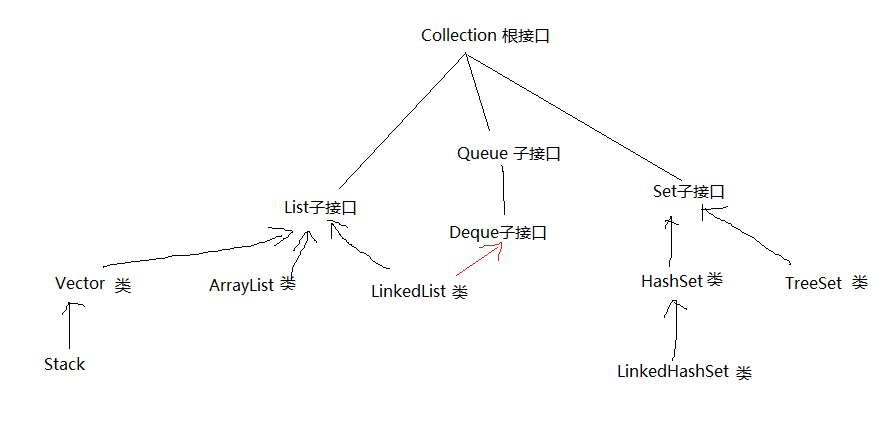
三、Map
Map 是存储一组键值对的,(key, value)称为键值对,也称为映射关系。这个系列的集合以 Map 接口为根接口。
Map 的特点:
- key 不能重复,如果重复,新 value 会覆盖原来的 value
- value 可以重复
3.1 Map 接口的方法(掌握)
1、增加
put(key, value)putAll(另一个Map)
package com.atguigu.map;
import org.junit.jupiter.api.Test;
import java.util.HashMap;
public class TestMap {
@Test
public void test1(){
//HashMap是所有Map中使用频率最高,面试也是被问的最多。
//HashMap<K,V> 有2个泛型字母,说明需要指定2个具体类型,一个是key对象的类型,一个是value对象的类型
//例如:存储咱们班同学的姓名以及 他/她对象的名字
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
System.out.println(map);
}
@Test
public void test2(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
HashMap<String,String> two =new HashMap<>();
two.put("小韩","翠花");
two.put("小涛","小薇");
two.put("小鹏","小薇");
//value可以重复
map.putAll(two);
System.out.println(map);
}
@Test
public void test3(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
map.put("李刚","翠花");
map.put("李刚","花花");
//如果key重复,新value会覆盖原来的value
System.out.println(map);
}
}2、删除
remove(key):找到 key 就删除一对(key,value)remove(key, value):必须找到(key , value)都对应的键值对才能删除,否则不删除clear():清空
package com.atguigu.map;
import org.junit.jupiter.api.Test;
import java.util.HashMap;
public class TestMap2 {
@Test
public void test(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
map.put("小韩","翠花");
map.put("小涛","小薇");
map.put("小鹏","小薇");
map.put("小杰","如花");
map.remove("小轩");//根据key,删除一对(key,value)
System.out.println(map);
//{李刚=null, null=小茹, 小韩=翠花, 小涛=小薇, 小杰=如花, 小鹏=小薇}
map.remove("小韩","翠花");//key和value对应
System.out.println(map);
//{李刚=null, null=小茹, 小涛=小薇, 小杰=如花, 小鹏=小薇}
map.remove("小涛","如花");//key和value对不上 ,不会删除
System.out.println(map);
//{李刚=null, null=小茹, 小涛=小薇, 小杰=如花, 小鹏=小薇}
}
}3、修改
replace(key, 新value)replace(key, 旧value,新value)replaceAll(BiFunction接口的实现类对象):需要编写有名或匿名的类实现 BiFunction 接口,重写apply(key, 旧value)返回值是新 value。
package com.atguigu.map;
import org.junit.jupiter.api.Test;
import java.util.HashMap;
import java.util.function.BiFunction;
public class TestMap3{
@Test
public void test1(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
map.put("小韩","翠花");
map.put("小涛","小薇");
map.put("小鹏","小薇");
map.put("小杰","如花");
map.replace("小轩", "坤坤");//用新value直接覆盖旧value
System.out.println(map);
}
@Test
public void test2(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
map.put("小韩","翠花");
map.put("小涛","小薇");
map.put("小鹏","小薇");
map.put("小杰","如花");
// map.replace("小轩","如花", "坤坤");
map.replace("小轩","小薇", "坤坤");
System.out.println(map);
//如果替换时,同时指定(key, 旧value,新value)要求(key,旧value)都要匹配
}
@Test
public void test3(){
HashMap<Integer,String> map =new HashMap<>();
map.put(1,"hello");
map.put(2,"world");
map.put(3,"java");
map.put(4,"atguigu");
//把key为偶数的单词,全部转为大写
/*
replaceAll方法的形参类型 BiFunction接口类型。
BiFunction<T, U, R>接口,也是函数式接口(只有1个抽象方法必须重写) R apply(T t, U u);
重写apply方法, 新value apply(key, 旧value)
*/
BiFunction<Integer,String,String> bi = new BiFunction<Integer, String, String>() {
@Override
public String apply(Integer key, String oldValue) {
return key % 2 == 0 ? oldValue.toUpperCase() : oldValue;
}
};
map.replaceAll(bi);
System.out.println(map);
//{1=hello, 2=WORLD, 3=java, 4=ATGUIGU}
}
}4、查询
- V
get(key):根据 key 返回 value - boolean
containsKey(key):是否包含 key - boolean
containsValue(value):是否包含 value - V
getOrDefault(key,默认value):根据 key 返回 value,如果 key 没找到,返回默认的 value - int
size():键值对数量
package com.atguigu.map;
import org.junit.jupiter.api.Test;
import java.util.HashMap;
public class TestMap4 {
@Test
public void test1(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
map.put("小韩","翠花");
map.put("小涛","小薇");
map.put("小鹏","小薇");
map.put("小杰","如花");
System.out.println("键值对的数量:" + map.size());//7
System.out.println(map.isEmpty());//false
System.out.println(map.containsKey("小轩"));//true
System.out.println(map.containsValue("如花"));//true
System.out.println(map.get("小轩"));//如花 根据key找value
System.out.println(map.getOrDefault("老宋","谷姐"));//谷姐 找不到用谷姐返回
System.out.println(map.getOrDefault("小轩","谷姐"));//如花
}
}5、遍历
- Set
<K>keySet():遍历所有 key - Collection
<V>values():遍历所有 value - Set
<Map.Entry__INLINE__0__>entrySet():遍历所有键值对 - void
forEach(BiConsumer接口的实现类对象):需要编写有名或匿名的类实现 BiConsumer 接口,重写accept(key, value)。
package com.atguigu.map;
import org.junit.jupiter.api.Test;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.function.BiConsumer;
public class TestMap5 {
@Test
public void test(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
map.put("小韩","翠花");
map.put("小涛","小薇");
map.put("小鹏","小薇");
map.put("小杰","如花");
//map不直接支持增强for循环遍历
//可以用别的方式使用增强for循环
//遍历所有key
//因为Map的key不能重复,所有的key组成的是一个Set
Set<String> keys = map.keySet();
System.out.println("keys的类型:" + keys.getClass());//获取这个keys对象的运行时类型,或new它的对象
//keys的类型:class java.util.HashMap$KeySet
for (String key : keys) {
System.out.println(key);
}
System.out.println("===============");
//遍历所有value
//因为Map的value可能重复,所有的value组成一个Collection系列的集合
Collection<String> values = map.values();
System.out.println("values的类型:" + values.getClass());
//values的类型:class java.util.HashMap$Values
for (String value : values) {
System.out.println(value);
}
System.out.println("======================");
//Map.Entry<String, String> 它是一种特殊的类型,它把 (key,value)组合到一起,构成一个对象,称为Entry对象。
//Map.Entry是Map接口的内部接口
Set<Map.Entry<String, String>> entries = map.entrySet();
/* for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getClass());
//class java.util.HashMap$Node
}*/
for (Map.Entry<String, String> entry : entries) {
System.out.println( "(" + entry +" )的key:" +entry.getKey() +",value:" +entry.getValue() );
}
System.out.println("======================");
/*
forEach方法的形参是BiConsumer类型,它也是一个函数式接口,BiConsumer<T, U> 抽象方法 void accept(T t, U u);
*/
BiConsumer<String,String> bi = new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println("key = " + key +", value = " + value);
}
};
map.forEach(bi);
}
}3.2 Map 的实现类(掌握)
- HashMap
<K,V>:哈希表 - Hashtable
<K,V>:哈希表 - LinkedHashMap
<K,V>:链式哈希表,可以体现(key,value)的添加顺序 - TreeMap
<K,V>:底层是红黑树,按照 key 元素的大小顺序排序,依赖于 Comparable 接口和 Comparator 接口 - Properties:它是 Hashtable 的子类,也是古老的。特殊在它的 key 和 value 一定是 String
Hashtable 和 HashMap:
- Hashtable:
- 旧的(命名不统一),线程安全的,效率低。
- 底层的数据结构:数组 + 单链表
- 不允许 key 和 value 为 null
- HashMap:
- 新的(命名统一),线程不安全的,效率高。
- 底层的数据结构:数组 + 单链表 + 红黑树(JDK7(含)之前也是数组 + 单链表)
- 允许 key 和 value 为 null
这么多 Map,怎么选择?
(1)Properties 和系统属性,或 xx.properties 有关
(2)TreeMap
<K,V>:只有对 key 的大小顺序有要求时才用它(3)LinkedHashMap
<K,V>:只有对(key,value)的添加顺序有要求时才用它(4)Hashtable:有线程安全隐患时用它。后期会有另一个代替它 ConcurrentHashMap。
Hashtable:卫生间很多坑,只要有 1 个人进入卫生间,整个卫生间都锁。
ConcurrentHashMap:每一个坑位单独锁。
(5)HashMap:如果没有上面这些特殊要求时,只要用 Map 都用它。
package com.atguigu.map;
import org.junit.jupiter.api.Test;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.*;
public class TestMapImpl {
@Test
public void test1(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
System.out.println(map);
}
@Test
public void test2(){
Hashtable<String,String> map =new Hashtable<>();
map.put("李刚",null);//报错
map.put("小轩","如花");
map.put(null,"小茹");;//报错
System.out.println(map);
}
@Test
public void test3(){
HashMap<String,String> map =new HashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
map.put("小韩","翠花");
map.put("小涛","小薇");
map.put("小鹏","小薇");
map.put("小杰","如花");
System.out.println(map);
//{李刚=null, null=小茹, 小轩=如花, 小韩=翠花, 小涛=小薇, 小杰=如花, 小鹏=小薇}
//无法体现添加顺序
}
@Test
public void test4(){
LinkedHashMap<String,String> map =new LinkedHashMap<>();
map.put("李刚",null);
map.put("小轩","如花");
map.put(null,"小茹");
map.put("小韩","翠花");
map.put("小涛","小薇");
map.put("小鹏","小薇");
map.put("小杰","如花");
System.out.println(map);
//{李刚=null, 小轩=如花, null=小茹, 小韩=翠花, 小涛=小薇, 小鹏=小薇, 小杰=如花}
}
@Test
public void test5(){
TreeMap<Integer, String> map = new TreeMap<>();
map.put(5, "小吴");
map.put(3, "小三");
map.put(1, "老大");
System.out.println(map);
}
@Test
public void test6(){
Properties properties = new Properties();
properties.setProperty("user","admin");
properties.setProperty("password","123");
System.out.println(properties.getProperty("user"));
}
@Test
public void test7()throws IOException {
/*
JUnit的单元测试方法,相对于当前module
*/
Properties properties = new Properties();
FileInputStream fis = new FileInputStream("one.properties");
properties.load(fis);
System.out.println(properties);
}
@Test
public void test8()throws IOException {
/*
JUnit的单元测试方法,相对于当前module
*/
Properties properties = new Properties();
FileInputStream fis = new FileInputStream("src/main/resources/jdbc.properties");
properties.load(fis);
System.out.println(properties);
//当前IDEA环境没问题,可以,但是实际开发项目不能这么写
}
@Test
public void test9()throws IOException {
Properties properties = new Properties();
ClassLoader loader = TestMapImpl.class.getClassLoader();
//上面这句代码是获取 加载当前TestMapImpl的类加载器对象。意思是用加载TestMapImpl的工具来加载jdbc.properties
properties.load(loader.getResourceAsStream("jdbc.properties"));
System.out.println(properties);
//当前IDEA环境没问题,可以,但是实际开发项目不能这么写
}
@Test
public void test10(){
Properties properties = System.getProperties();
//获取所有的系统属性
// properties是一个Map
// properties.entrySet().var自动出来左边
// properties.entrySet();按Ctrl + Alt + V 自动出来左边
Set<Map.Entry<Object, Object>> entries = properties.entrySet();
for (Map.Entry<Object, Object> entry : entries) {
System.out.println(entry);
}
}
}3.3 Set 和 Map(知道就行)
- HashSet 和 HashMap:HashSet 的内部/底层是 HashMap
- LinkedHashSet 和 LinkedHashMap:LinkedHashSet 的内部/底层是 LinkedHashMap
- TreeSet 和 TreeMap:TreeSet 的内部/底层是 TreeMap
package com.atguigu.set;
import org.junit.jupiter.api.Test;
import java.util.HashSet;
public class TestSetMap {
@Test
public void test1(){
HashSet<String> set = new HashSet<>();
set.add("张三");
set.add("李四");
set.add("王五");
set.add("赵六");
/*
1、当我们创建HashSet时,其实底层是创建了一个HashMap
public HashSet() {
map = new HashMap<>();
}
2、我们存到Set的是单个单个的对象,而Map是存储键值对的,那么另一本从哪里来?
private static final Object PRESENT = new Object(); //常量对象
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
*/
}
}四、迭代器
4.1 Iterable 和 Iterator 接口(掌握如何使用 hasNext 和 next 即可)
Collection 系列和 Map 系列是 Java 中集合的 2 大家族。Collection 系列的集合支持使用迭代器和增强 for 循环来遍历。而 Map 系列的集合不直接支持迭代器和增强 for 循环来遍历,必须通过转换才能使用他们遍历。
迭代器的接口:Iterator
可迭代的接口:Iterable,只有实现这个接口的集合才能使用 foreach 循环遍历,或者才能使用 Iterator 遍历。因为实现 Iterable 接口,必须重写一个 Iterator<T> iterator()方法,这个方法用于返回一个 Iterator 的对象。
| Iterable | Iterator | |
|---|---|---|
| 词性 | 形容词 | 名词 |
| 表示 | 某个集合可迭代的。可以使用 foreach 或 Iterator 来遍历 | 用来遍历集合的工具 |
| 谁来实现它 | 各种集合,通常是 Collection 系列集合 | 集合里面的内部类来实现它 |
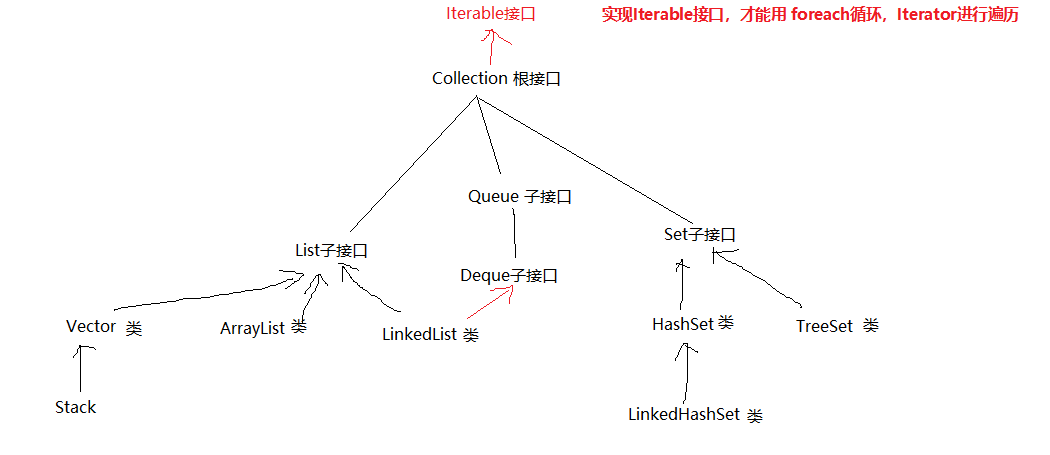
为什么这些迭代器,要以内部类的形式存在集合中,而不是独立的外部类呢?
- 内部类可以直接访问外部类的成员,包括私有的。
- 每一种集合的实际遍历方式都不同,所以具体的迭代器类是没有通用性的场景。
- 此时把迭代器的实现放到集合内部,就可以遵循高内聚的开发原则。
为什么这些迭代器在各个集合内部完全不同,它们要实现相同的 Iterator 接口呢?
希望集合虽然不同,数据结构不同,但是遍历集合的方式尽量统一。大家都用
hasNext()和next()。这里遵循了低耦合的开发原则。我们实际用的时候,只要与 Iterator 接口耦合,与实现的内部的实现类完全解耦。
package com.atguigu.iterable;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Objects;
//<E>代表将来存到集合中的元素的类型
public class MyArrayList<E> implements Iterable<E>{
private Object[] elements= new Object[10];
private int size;//代表实际元素的个数
public void add(E e){//末尾位置添加
//抽取一段代码构成一个新方法的快捷键是Ctrl + Alt + M
grow();
elements[size++] = e;
}
private void grow() {
if(size >= elements.length){
//扩容
// elements = Arrays.copyOf(elements, elements.length + 1);//一次增加1个,频率非常高
// elements = Arrays.copyOf(elements, elements.length*2);//2倍扩容
// elements = Arrays.copyOf(elements, elements.length<<1);//2倍扩容
// elements = Arrays.copyOf(elements, elements.length + elements.length/2);//1.5倍扩容
elements = Arrays.copyOf(elements, elements.length + (elements.length>>1));//1.5倍扩容
}
}
public void add(int index, E e){//插入
//添加时 index的位置必须是 [0, size]
if(index<0 || index>size){
throw new IndexOutOfBoundsException();
}
//可能需要扩容
grow();
//[index, size-1]范围的元素需要右移
/*
假设: elements的长度是10, size = 5, index = 1
需要移动的元素:[1][2][3][4]
移动size-index
elements的长度是10, size = 7, index = 3
需要移动的元素:[3][4][5][6]
移动size-index
*/
System.arraycopy(elements, index, elements, index+1, size-index);
//新元素放到index位置
elements[index] = e;
//元素个数增加
size++;
}
public void remove(int index){//删除[index]位置的元素
//删除时 index的位置必须是 [0, size-1]
if(index<0 || index>=size){
throw new IndexOutOfBoundsException();
}
//[index, size-1]范围的元素要左移
/*
假设: elements的长度是10, size = 5, index = 1
需要移动的元素:[2][3][4]
移动size-index-1
elements的长度是10, size = 7, index = 3
需要移动的元素:[4][5][6]
移动size-index-1
*/
System.arraycopy(elements, index+1, elements, index, size-index-1);
//元素个数减少
size--;
}
public void remove(Object target) {
//查找target在数组的位置
int index = indexOf(target);
if(index != -1) {
remove(index);
}
}
public int indexOf(Object target){
/* if(target == null){
for (int i = 0; i < elements.length; i++) {
if(elements[i] == target){
return i;
}
}
}else {
//返回target在数组中的下标,找到返回下标,没找到返回-1
for (int i = 0; i < elements.length; i++) {
// if(elements[i] == target){//太严格了,比较地址值
if (target.equals(elements[i])) {
return i;
}
}
}*/
for (int i = 0; i < elements.length; i++) {
if (Objects.equals(elements[i], target)) {
return i;
}
}
return -1;
}
@Override
public String toString() {
/*return "MyArrayList{" +
"elements=" + Arrays.toString(elements) +
", size=" + size +
'}';*/
//Arrays.copyOf(elements,size) 复制size个元素
// Arrays.toString(数组)把数组的元素拼接为[元素1,元素2]
return Arrays.toString(Arrays.copyOf(elements,size));
}
@Override
public Iterator<E> iterator() {
return new MyIterator<E>();
}
private class MyIterator<E> implements Iterator<E>{
int index = 0;
@Override
public boolean hasNext() {
return index<size;
}
@Override
public E next() {
return (E) elements[index++];
}
}
}package com.atguigu.iterable;
import org.junit.jupiter.api.Test;
import java.util.Iterator;
public class TestMyArrayList {
@Test
public void test1(){
MyArrayList<String> list = new MyArrayList<>();
list.add("hello");
list.add("java");
list.add("world");
list.add("atguigu");
for (Object object : list) {
System.out.println(object);
}
}
@Test
public void test2(){
MyArrayList<String> list = new MyArrayList<>();
list.add("hello");
list.add("java");
list.add("world");
list.add("atguigu");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String s = iterator.next();
System.out.println(s);
}
}
}4.2 集合的快速失败机制(记结论)
package com.atguigu.fail;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Iterator;
public class TestFail {
@Test
public void test1(){
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
list.add("java");
//演示问题:删除包含o字母的单词
for (String s : list) {
if(s.contains("o")){
list.remove(s);//java.util.ConcurrentModificationException 并发修改异常
}
}
}
@Test
public void test2(){
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
list.add("java");
//演示问题:删除包含o字母的单词
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String s = iterator.next();
if(s.contains("o")){
list.remove(s);//java.util.ConcurrentModificationException 并发修改异常
}
}
}
@Test
public void test3(){
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
//演示问题:删除包含o字母的单词
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String s = iterator.next();
if(s.contains("o")){
list.remove(s);
}
}
System.out.println(list);//[world] 漏删
}
}上面的代码
尽快的发生 ConcurrentModificationException,告诉程序员这个代码是有问题,而不是冒着将来有风险,有隐患的问题继续往下执行。例如:出现漏删,数据不一致的问题。
每一次迭代器在调用
next()方法时,都会检查 modCount 和 expectedModCount 是不是一致。
- modCount:集合用于记录元素结构发生变化的次数。当元素增加、删除、排序等变动时,modCount 都会加 1.
- mod:modify 的缩写,代表修改
- count:次数
- expectedModCount:迭代器用于记录它期待、预计、预估的 modCount 值
- 当我们创建迭代器对象时,expectedModCount 会被初始化为 modCount 值
- 但是如果在迭代器工作的过程中,我们调用了集合的 add、remove、sort 等方法,就会导致 modCount 变了。此时 expectedModCount 就和 modCount 不一致了。
- 除非让迭代器的 expectedModCount 与集合的 modCount 再同步一次
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}分析过程请看《尚硅谷Java 基础第 11 章_02 迭代器.pptx》
就算刚才的原理和过程没有跟上,最终你要记住一个结论:
在 foreach 和 Iterator 遍历的过程中,
绝对绝对绝对不可以调用集合的 add、remove、sort 等方法如果要删除集合的元素,(请看下面的代码)
- Iterator 遍历 + 迭代器的 remove 方法
- 不要用迭代器,用集合的 removeIf 方法来删除
@Test
public void test4(){
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
list.add("java");
list.add("ok");
list.add("chai");
//演示问题:删除包含o字母的单词
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String s = iterator.next();
if(s.contains("o")){
//注意这里不同
iterator.remove();//不是集合的remove
}
}
System.out.println(list);
}
@Test
public void test5(){
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
list.add("java");
list.add("ok");
list.add("chai");
//演示问题:删除包含o字母的单词
Predicate<String> p = new Predicate<String>() {
@Override
public boolean test(String s) {
return s.contains("o");
}
};
list.removeIf(p);
System.out.println(list);
//[java, chai]
}五、Collections 工具类
package com.atguigu.util;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class TestCollections {
@Test
public void test1(){
//public static <T> boolean addAll(Collection<? super T> c, T... elements)
//给一个Collection系列的集合(List、Set、Queue等)添加多个元素
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world");
System.out.println(list);
}
@Test
public void test2(){
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 5,7,8,2,1,3);
System.out.println(list);
//方案一:工具类有sort方法
//public static <T extends Comparable<? super T>> void sort(List<T> list)
//public static <T> void sort(List<T> list, Comparator<? super T> c)
Collections.sort(list);
System.out.println(list);//[1, 2, 3, 5, 7, 8]
Comparator<Integer> c = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
};
Collections.sort(list, c);
System.out.println(list);
//方案二:List集合自己有sort方法
list.sort(null);
System.out.println(list);//自然排序
list.sort(c);
System.out.println(list);//定制比较
}
@Test
public void test3() {
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 5, 7, 8, 2, 1, 3);
list.sort(null);
System.out.println(list);//[1, 2, 3, 5, 7, 8]
/*
public static <T> int binarySearch(List<? extends Comparable<? super T>> list,T key)
public static <T> int binarySearch(List<? extends T> list, T key, Comparator<? super T> c)
*/
Integer target = 3;
int index = Collections.binarySearch(list, target);
System.out.println("index = " + index);//index = 2
}
@Test
public void test4(){
/*
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)
public static <T> T max(Collection<? extends T> coll, Comparator<? super T> comp)
*/
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 5, 7, 8, 2, 1, 3);
Integer max = Collections.max(list);
System.out.println("max = " + max);//max = 8
}
@Test
public void test5(){
//public static void shuffle(List<?> list) :扰乱集合元素的顺序,类似于洗牌
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3,4, 5, 6);
System.out.println(list);//[1, 2, 3, 4, 5, 6]
Collections.shuffle(list);//随机打乱
System.out.println(list);
}
@Test
public void test6(){
//public static int frequency(Collection<?> c, Object o)
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 1, 5,1,3,1);
int count = Collections.frequency(list, 1);
System.out.println("count = " + count);//count = 4
}
}